




- @qq_51957239
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
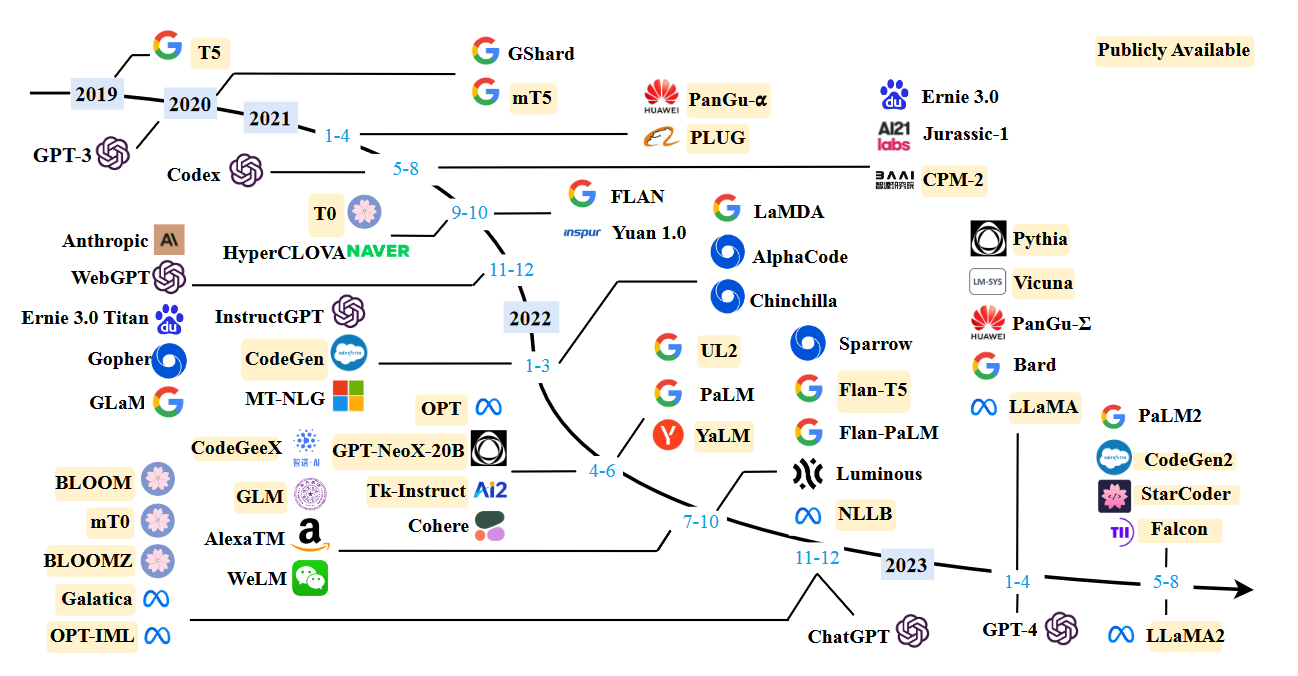
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示了惊人的潜力。从生成文本和对话系统到更为复杂的任务,如文本摘要、机器翻译和情感分析,LLM正在逐渐改变我们与数字世界的互动方式
本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实战,具体用一个预测房价的例子使用上述方法。
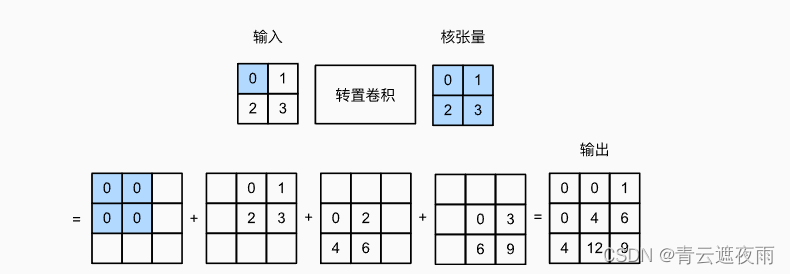
转置卷积(Transposed Convolution),也称为反卷积(Deconvolution),是卷积神经网络(CNN)中的一种操作,它可以将一个低维度的特征图(如卷积层的输出)转换为更高维度的特征图(如上一层的输入)。转置卷积操作通常用于图像分割、生成对抗网络(GAN)和语音识别等任务中。在传统卷积操作中,我们使用一个滑动窗口(卷积核)来从输入图像中提取特征。而在转置卷积中,我们使用一个滑
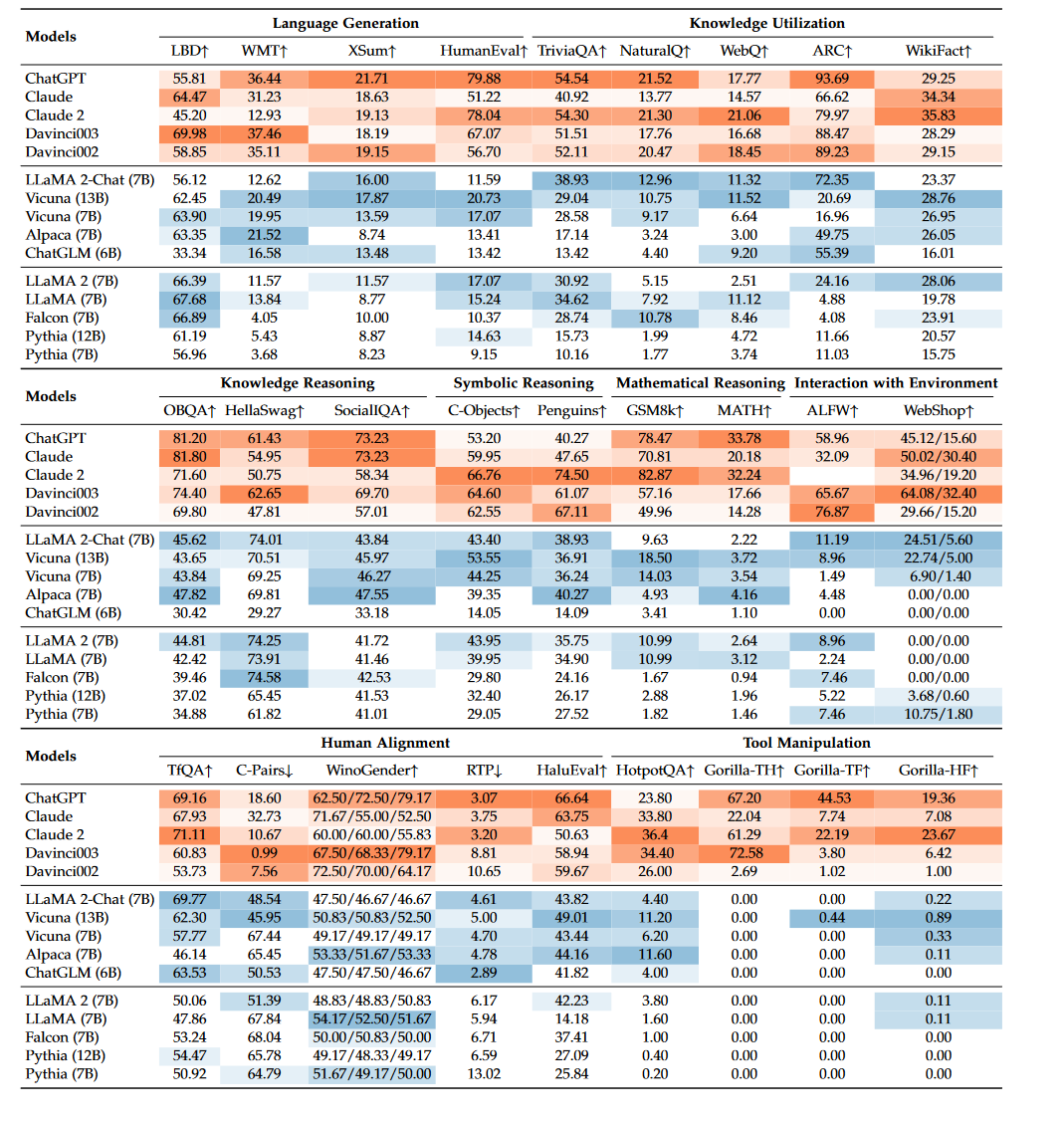
为了检验LLM的有效性和优越性,已经提出了大量任务和基准,用于进行经验能力评估和分析。在本节中,我们首先介绍了LLM在语言生成和理解方面的三种基本能力评估类型,然后介绍了几种具有更复杂设置或目标的LLM的高级能力评估,最后讨论了现有的基准、评估方法和经验分析。
GRPO是一种高效的强化学习策略优化方法,专为节省训练成本设计。它通过生成多样化候选输出并用奖励函数评估,替代传统评论家模型。核心机制是采样多组输出后选择高质量回答进行学习,利用组内奖励计算优势函数并优化策略。该方法采用KL散度惩罚确保训练稳定性,避免了额外价值函数的计算负担。GRPO特别适合解决语言模型的稀疏奖励问题,能有效探索输出空间,在DeepSeek-R1系列开发中成功应用。相比传统方法,
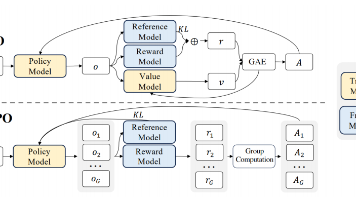
GRPO是一种高效的强化学习策略优化方法,专为节省训练成本设计。它通过生成多样化候选输出并用奖励函数评估,替代传统评论家模型。核心机制是采样多组输出后选择高质量回答进行学习,利用组内奖励计算优势函数并优化策略。该方法采用KL散度惩罚确保训练稳定性,避免了额外价值函数的计算负担。GRPO特别适合解决语言模型的稀疏奖励问题,能有效探索输出空间,在DeepSeek-R1系列开发中成功应用。相比传统方法,
本节将介绍如何使用卷积神经网络,自动将一个图像中的风格应用在另一图像之上,即风格迁移(style transfer) (Gatys et al., 2016)。 这里我们需要两张输入图像:一张是内容图像,另一张是风格图像。 我们将使用神经网络修改内容图像,使其在风格上接近风格图像。 例如, 图中的内容图像为本书作者在西雅图郊区的雷尼尔山国家公园拍摄的风景照,而风格图像则是一幅主题为秋天橡树的油画。

门控循环神经网络(Gated Recurrent Neural Network,简称“门控循环神经网络”或“门循环神经网络”)是一种改进的循环神经网络(RNN)架构。它包含了一些门控机制,可以更好地捕捉时间序列数据中的长期依赖关系。门控循环神经网络最早由Hochreiter和Schmidhuber在1997年提出,但是由于当时缺乏计算能力和数据集,它并没有得到广泛应用。后来,在2014年,Cho等

Inception模块是GoogleNet中的一个核心组成部分,用于提取图像特征。该模块采用并行的多个卷积层和池化层来提取不同尺度的特征,然后将它们在通道维度上进行拼接,得到更丰富的特征表达。一个基本的Inception模块包含了四个分支(Branch),每个分支都有不同的卷积核或者池化核,如下图所示:在这个模块中,我们可以看到分支1、2、3都是卷积层,分支4则是最大池化层,其目的是提取图像中不同
深度学习神经网络复现