




- @qq_49980458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
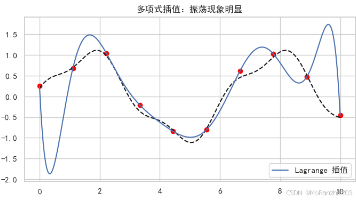
在科学计算与数据分析中,插值(Interpolation)是一类重要的工具,用来在已知数据点之间推测未知点的函数值。SciPy 提供了丰富的插值函数接口,可以轻松实现从一维到多维的插值运算。本文将结合数学公式、SciPy 函数与 Python 可视化案例,系统梳理常见插值方法。
本文将带你从数学建模角度完整解析《2048》游戏的设计逻辑,结合 Python 实现代码,逐步还原游戏从状态表示、移动合并、胜负判断到控制循环的全过程。

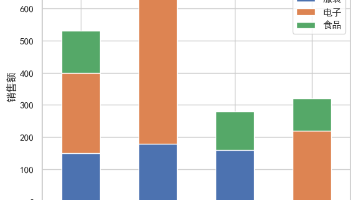
本文以零售业务为例,完整展示 Pandas 在数据导入、清洗、汇总分析与可视化中的综合应用。从原始数据到分析洞察,帮助读者掌握一条清晰、系统的数据分析流程,提升从“看懂数据”到“用好数据”的实战能力。
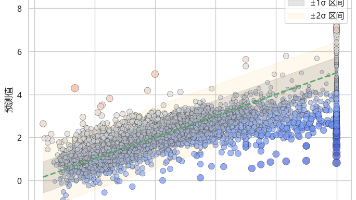
随机梯度下降(SGD)是一种高效的优化方法,适用于大规模数据的回归和分类任务。本文介绍了 SGD 的算法原理、数学模型、实现流程及参数解析,并通过 Python `scikit-learn` 案例展示其在回归(加州房价预测)与分类(鸢尾花分类)中的应用与可视化效果。
灰度化、二值化与阈值处理常用于目标区域提取、文档图像处理、前景分离、掩码构造以及图像分割的前期准备。在 Pillow 中,这些操作可以通过 `convert()`、`point()` 以及结合 NumPy 的像素级逻辑运算来实现。本章将围绕灰度图的生成、阈值映射、二值化处理、掩码生成以及简单的伪彩色可视化展开,说明图像如何从连续的颜色表示逐步过渡为更明确的结构表达。整体思路仍然延续前文,即从图像的

本文以零售业务为例,完整展示 Pandas 在数据导入、清洗、汇总分析与可视化中的综合应用。从原始数据到分析洞察,帮助读者掌握一条清晰、系统的数据分析流程,提升从“看懂数据”到“用好数据”的实战能力。
NumPy 不仅是科学计算和线性代数的重要工具,也是 数据分析与图像处理 的基础。依托其高效的数组操作、向量化计算和广播机制,我们能够快速处理表格数据、时间序列以及图像像素矩阵。本篇作为系列的收官篇,将展示 NumPy 在数据分析和图像处理中的实际应用。本文将围绕以下几个方面展开:1. NumPy 在数据分析中的常见应用,2. 数据分析示例,3. 图像处理的基本概念与数组表示,4. 图像操作与增强

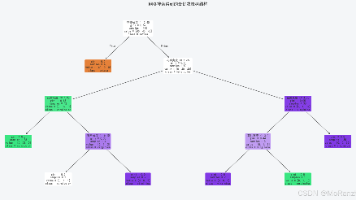
决策树(Decision Tree)是机器学习中最经典的一类分类模型。它的优势非常直接:规则清晰、可解释性强、上手门槛低;与此同时,它也有一个非常典型的问题,那就是容易过拟合。这也是学习 DecisionTreeClassifier 的意义所在。学习决策树,不只是学会调用一个分类器,更是在理解监督学习中的几个核心问题:模型如何利用特征逐步完成分类,什么是节点纯度,为什么它决定了划分效果,以及为什么
梯度提升(Gradient Boosting, GB)是一种集成学习算法,通过迭代优化残差逐步提升模型性能,适用于回归和分类任务。它强调精度,适合复杂非线性关系建模。关键参数包括学习率、迭代次数和树深度。与随机森林相比,GB 更注重预测精度,可结合 XGBoost、LightGBM、CatBoost 等高效实现应用于金融风险预测、医疗数据建模、销售预测及图像特征分析等场景。
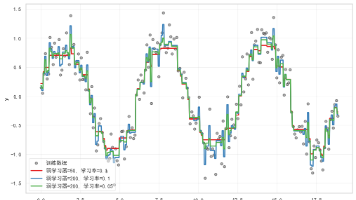
本文介绍了 scikit-learn 的 LogisticRegression 逻辑回归分类算法。虽然名称中带有“回归”,但它本质上是一个经典的分类模型,主要用于二分类任务,同时也能够扩展到多分类问题。文章将从算法原理、主要参数、代码示例、可视化分析以及适用场景几个方面展开,帮助读者系统理解 LogisticRegression 在 scikit-learn 中的使用方式与实践价值。