- @qq_47997583
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今天在实验室电脑新装的Ubuntu系统上第一次git clone代码出了这个报错,才想起来还没有在这个系统上配置ssh连接我的github。这里记录一下过程,方便之后再新电脑上再配置时方便参考。
1.理论本节介绍的是REINFORCE算法,其在估计每个状态动作对的奖励时不使用整个回合的奖励,而是该时刻开始之后的累计奖励作为权值。∇θJ(θ)=Eπθ[∑t=0T(∑t′=tTγt′−trt′)∇θlogπθ(at∣st)]\nabla_{\theta} J(\theta)=\mathbb{E}_{\pi_{\theta}}\left[\sum_{t=0}^{T}\left(\sum_{t^

马尔可夫决策过程1.公式总结2.代码实践2.1 计算序列的回报2.2 利用贝尔曼方程的矩阵形式计算解析解2.3 解析法计算MDP中每个状态价值2.4 使用蒙特卡洛方法计算MDP的状态价值2.5 估算策略的占用度量
1.查看git日志2.文件更改添加一部分信息后文件会变蓝新创建一个文件夹会提问要不要加入到Git中如果选择cancel文件夹会继续是红色的然后不加到Git仓库选择add则文件名变绿3.提交更改左键双击可以查看更改的具体信息填写提交的备注信息然后点击commit可以看到文件颜色消失下面是未push时的截图然后输入账号密码可以看到提交成功...
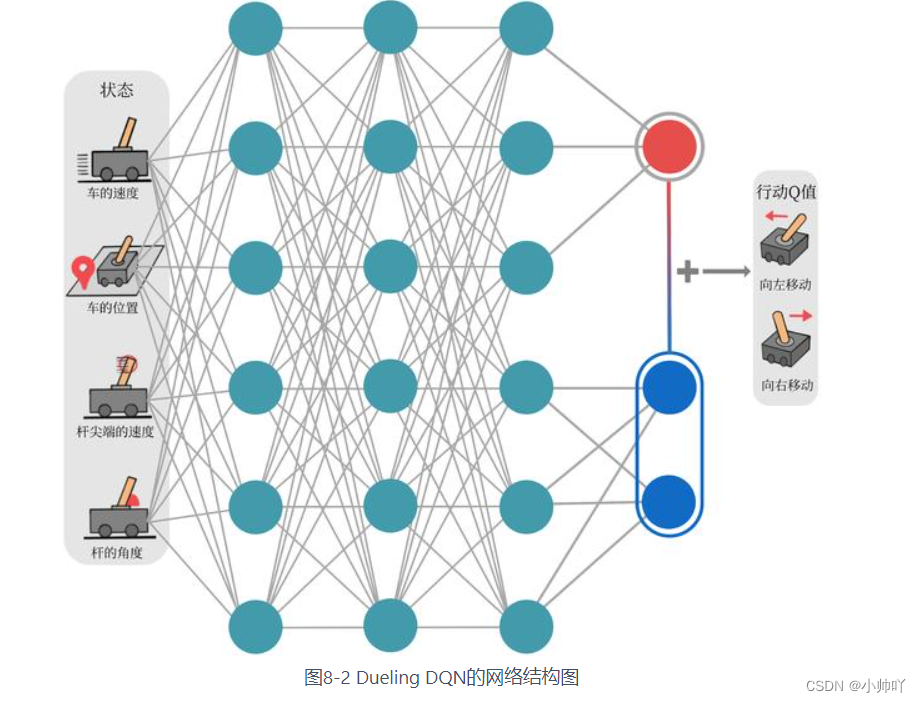
文章目录第八章:DQN改进算法1.理论部分1.1 Double DQN1.2 Dueling DQN2.实践部分第八章:DQN改进算法1.理论部分本部分主要是double DQN与Dueling DQN1.1 Double DQN回顾:首先回顾一下普通的DQN是如何更新参数的Q(s,a)←Q(s,a)+α[r+γmaxa′∈AQ(s′,a′)−Q(s,a)]Q(s, a) \leftarrow
总结分层强化学习中的知识,持续更新~~~
分层强化学习HAC算法的代码实现过程

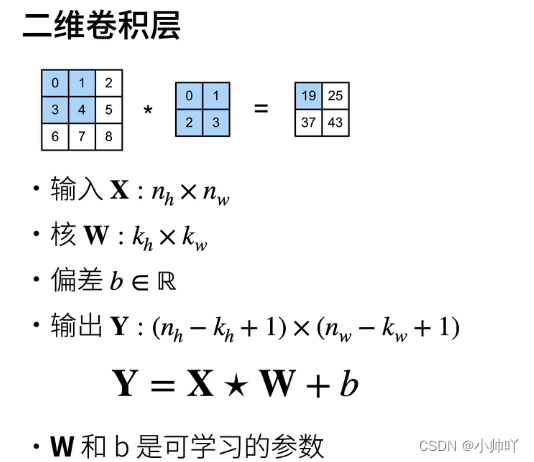
卷积神经网络构架中的涉及维度间转换的计算问题,包含实例代码
第十章:Actor-Critic算法1.理论Actor-Critic 算法本质上是基于策略的算法,因为这系列算法都是去优化一个带参数的策略,只是其中会额外学习价值函数来帮助策略函数的学习。在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报,来指导策略的更新。而值函数的概念正是基于期望回报,我们能不能考虑拟合一个值函数来指导策略进行学习呢?这正是 Actor-Critic 算法所做的。在

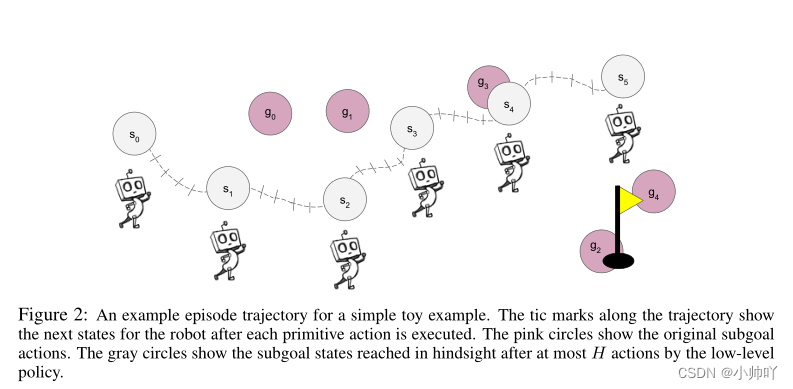
与HIRO一样,本文解决的同样是分层强化学习中不同层级策略学习所存在的non-stationary(非平稳问题),但是用了完全不同思想的方法。分层强化学习通过将任务分解成多个子任务,样本利用率更高。然而,在分层结构中,上层的转移函数取决于下层的策略,当所有层级的策略同时进行训练时,下层策略不断更新,这就导致了上层的转移函数会随之不断变化,在这样的非平稳环境中,智能体很难学习到最优策略,这就是分层强