




- @qq_45404396
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.马赛克效果马赛克的基本原理就是,用某一个区域的某一个像素点替代这个区域所有的像素点,从而导致图片出现模糊的效果,如下;import cv2# 马赛克效果img = cv2.imread(filename='../anqila21.jpg',flags=1)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]flag = 2# 系数,系
Cause: java.lang.ClassNotFoundException: Cannot find class: com.github.pagehelper
1.马赛克效果马赛克的基本原理就是,用某一个区域的某一个像素点替代这个区域所有的像素点,从而导致图片出现模糊的效果,如下;import cv2# 马赛克效果img = cv2.imread(filename='../anqila21.jpg',flags=1)imgInfo = img.shapeheight = imgInfo[0]width = imgInfo[1]flag = 2# 系数,系
虎牙上面有许多不错的视频,可是怎样下载这些视频呢?今天,小编教你一招,只需读者输入一个链接,就能实现虎牙视频的下载。
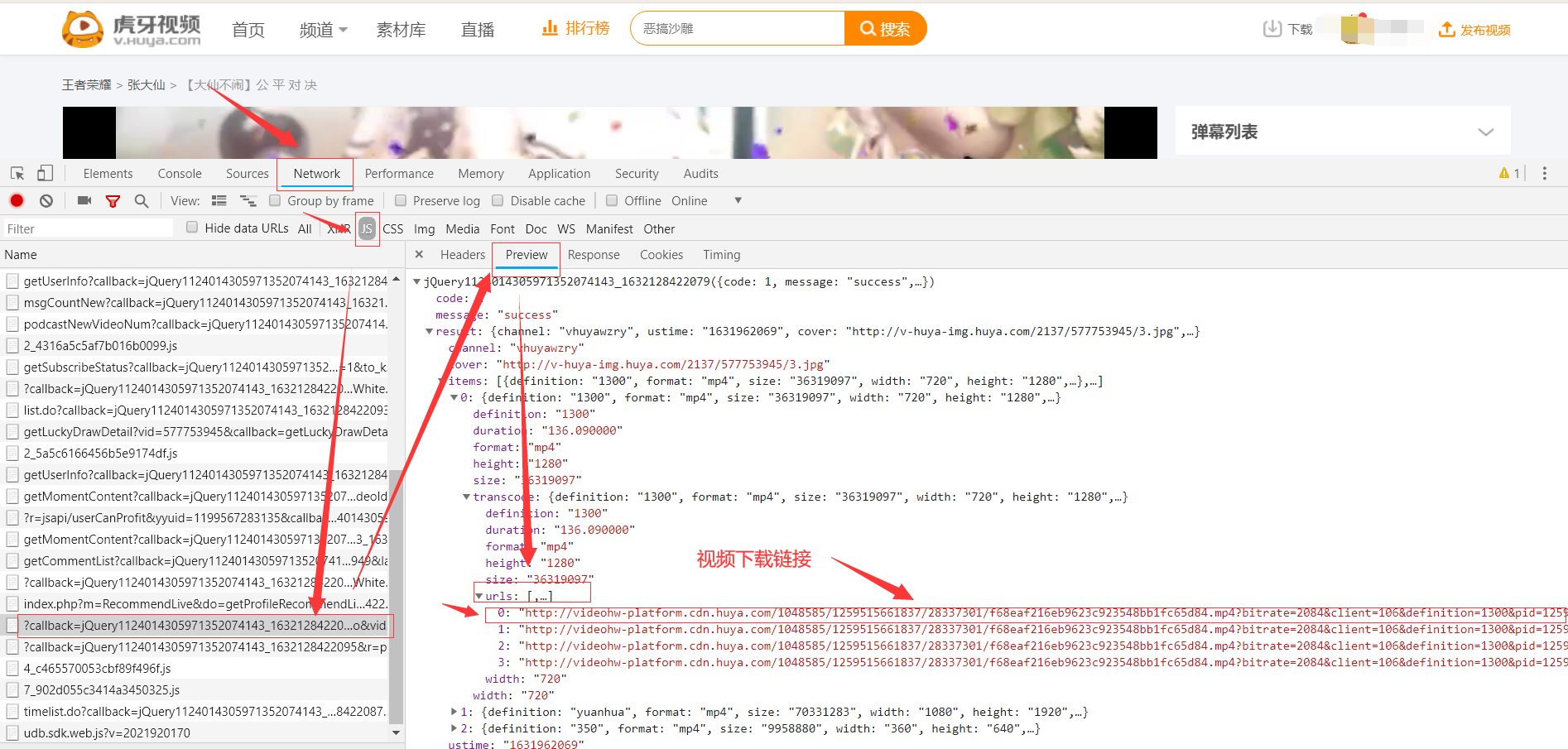
文章内容可能存在版权问题,为此,小编不提供相关实现代码,只是从js逆向说一说到底怎样实现这个的过程,希望能够帮助到那些正在做js逆向相关操作的读者,需要代码的读者单独私信我吧!不过,需要注意的是:代码仅供学习,不能用于商业活动,望读者切记。。
Python爬虫是一个神奇的东西,但是经常会面临爬不到数据等问题,今天,小编就教读者怎样解决这些问题,不过,或许讲到的面还不全面,希望大家理解。
最近在看西瓜视频,觉得上面的视频很有一些意思,想把这些视频下载下来,但是电脑上西瓜视频没有pc端,只有网页端,于是写了这篇博客,欢迎有兴趣的读者来看小编的博客喔!
昨天小编在CSDN问答上遇到了如下这个问题复制了问答上楼主的代码,的确响应状态码为406后面小编仔细检查了一下这个代码里面的请求头header里面的参数,突然发现这个Accept字段里面的值不是标准的格式,也就是他的值格式有问题。他的代码里请求头header参数Accept的值为application / json, text / plain, * / * ,可以发现这个值按标准写法应该是这样的。
对音频文件剪辑、转换音频文件格式你还在使用相应编辑软件进行操作吗?为什么不使用Python代码来解决呢?