




- @qq_44273739
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在接口开发过程中,如果数据源的数据是连续插入进入源表中,并且当新数据到达时,老数据不会被删除。而业务处理过程中,只需要最新一批的数据时,我们可以对数据的create_time进行开窗倒序排序,然后只取rn=1的数据,保证每次取得的结果都是最新数据。其中还分两种不同的业务需求:

大模型训推一体机” 这个概念指的是用于大规模机器学习模型训练和推理的一体化系统或平台。在人工智能领域,特别是深度学习中,随着模型规模的增大(比如参数量达到数十亿甚至更多),对计算资源的需求也急剧增加。因此,开发专门的硬件和系统来支持这些大模型的训练和部署变得尤为重要。随着技术的发展,训推一体机将会成为构建和部署复杂AI应用的关键基础设施之一。

在接口开发过程中,如果数据源的数据是连续插入进入源表中,并且当新数据到达时,老数据不会被删除。而业务处理过程中,只需要最新一批的数据时,我们可以对数据的create_time进行开窗倒序排序,然后只取rn=1的数据,保证每次取得的结果都是最新数据。其中还分两种不同的业务需求:
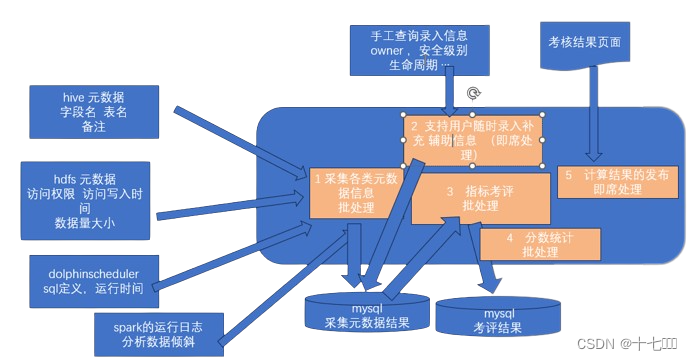
通过设定各种治理项指标,对指标进行考核评分排名,结果导向倒逼开发人员不断改进数据治理的各项问题。优点:成本低,直击问题本身。提供一个大而全的平台,将数据建模、数据开发、数据运营、指标可视化…优点是好用,缺点是开发周期长,租用费用贵。
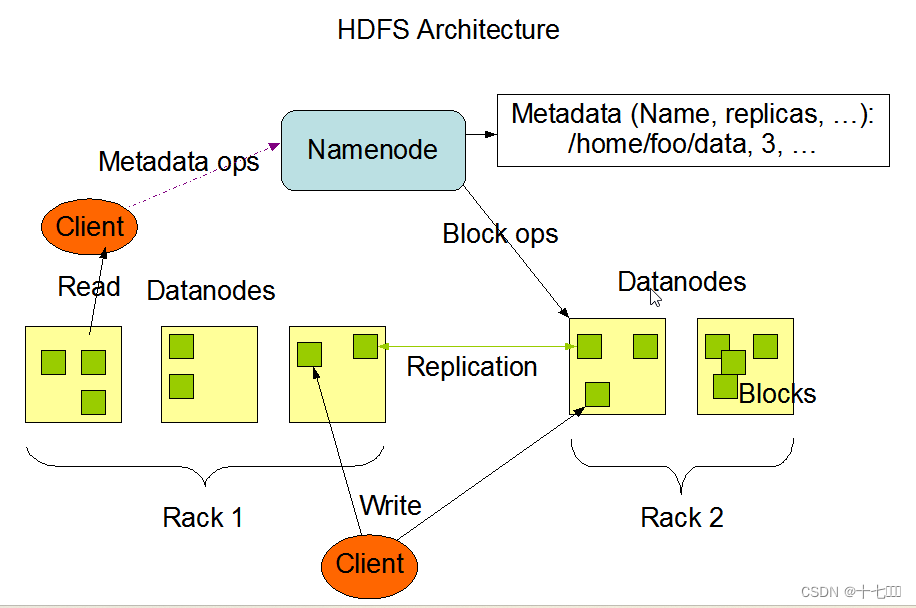
全称为Hadoop distributed file system, 是一个分布式文件系统,通过目录树来定位文件。适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不能改变。优点:高容错性:通过增加副本的形式,提高容错性;副本丢失后会自动补全适合处理大数据:数据规模达到PB级别,文件数量达到9亿个可以构建在廉价机器上缺点:不适合低延时数据访问,比如毫秒级的存储数据。无法高效对大量小文
在下载了python3.7和人脸识别所需的opencv-python和opencv-contrib-python后,我尝试在我的mac笔记本的pycharm软件中运行一段调用摄像头进行人脸识别的python脚本。

大模型训推一体机” 这个概念指的是用于大规模机器学习模型训练和推理的一体化系统或平台。在人工智能领域,特别是深度学习中,随着模型规模的增大(比如参数量达到数十亿甚至更多),对计算资源的需求也急剧增加。因此,开发专门的硬件和系统来支持这些大模型的训练和部署变得尤为重要。随着技术的发展,训推一体机将会成为构建和部署复杂AI应用的关键基础设施之一。
大模型训推一体机” 这个概念指的是用于大规模机器学习模型训练和推理的一体化系统或平台。在人工智能领域,特别是深度学习中,随着模型规模的增大(比如参数量达到数十亿甚至更多),对计算资源的需求也急剧增加。因此,开发专门的硬件和系统来支持这些大模型的训练和部署变得尤为重要。随着技术的发展,训推一体机将会成为构建和部署复杂AI应用的关键基础设施之一。