




- @qq_43840665
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定义:NVIDIA GPU 中的基本执行单元,1 个 Warp = 32 个 Thread定位:Warp 是硬件调度单元,对程序员透明,由 SM 自动将 Thread 分组形成与线程层次的关系:Block 是逻辑概念(程序员定义),Warp 是物理概念(硬件强制)

摘要: DeepSeek团队提出的流形约束超连接(mHC)技术,通过将超连接(HC)的无约束连接矩阵投影到双随机矩阵流形,解决了大模型训练中的稳定性与性能矛盾。mHC在保留多流架构表达能力的同时,修复了恒等映射属性,使信号增益从HC的3000倍降至1.6倍,实现平稳收敛。结合内核融合等工程优化,额外开销仅6.7%。实验显示,mHC在27B参数模型上全面超越基线,推理任务性能提升1.6%-2.3%,

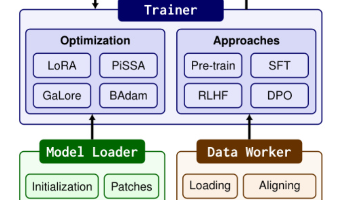
阿里云DSW 提供多种 预装主流框架的镜像(类似Docker容器模板)。模块化设计(四大核心组件,官方为三个,不包含封装的WebUI)LlamaFactory 方案调研。LLaMA-Factory理论篇。LLaMA-Factory理论篇。LlamaFactory 框架。安装LLaMA-Factory。使用LLaMA-Factory。LlamaFactory 框架。安装LLaMA-Factory。使
混合编程模型(Hybrid Programming Model)混合编程模型(Hybrid Programming Model)自动映射算法(Auto-Mapping algorithm)自动映射算法(Auto-Mapping algorithm)3D并行混合引擎(3D‑HybridEngine)3D并行混合引擎(3D‑HybridEngine)根本原因:存储需求的不同源于模型是。HybridFl
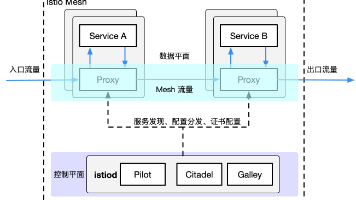
Pilot与Envoy代理之间维持一个gRPC长连接,所有配置的分发都基于此链接的一个Stream,配置的下发采用异步方式。少年,我观你骨骼清奇,颖悟绝伦,必成人中龙凤。
系列综述:💞目的:本系列是个人整理为了学习VLAN相关知识的,整理期间苛求每个知识点,平衡理解简易度与深入程度。🥰来源:材料主要源于进行的,每个知识点的修正和深入主要参考各平台大佬的文章,其中也可能含有少量的个人实验自证。🤭结语:如果有帮到你的地方,就和!!!!,后续继续完善和扩充👍(●’◡’●)

git本地项目快速push到远程仓库
什么是计算机网络?计算机网络是一个将分散的、具有独立功能的计算机系统,通过通信设备与线路连接起来,有功能完善的软件实现资源共享和信息传递的系统计算机网络和操作系统的区别操作系统是提高端系统内硬件资源的利用率计算机网络是提高由网络连接的整个系统的软件资源、硬件资源和数据资源的利用率...
阿里云DSW 提供多种 预装主流框架的镜像(类似Docker容器模板)。模块化设计(四大核心组件,官方为三个,不包含封装的WebUI)LlamaFactory 方案调研。LLaMA-Factory理论篇。LLaMA-Factory理论篇。LlamaFactory 框架。安装LLaMA-Factory。使用LLaMA-Factory。LlamaFactory 框架。安装LLaMA-Factory。使
系列综述:💞目的:本系列是个人整理为了云计算学习的,整理期间苛求每个知识点,平衡理解简易度与深入程度。🥰来源:材料主要源于–团队核心技术大佬提供的资料–进行的,每个知识点的修正和深入主要参考各平台专业人员的文章,其中也可能含有少量的个人实验自证。🤭结语:如果有帮到你的地方,就和!!!!,后续继续完善和扩充👍(●’◡’●)
