
写文章




- @qq_42740834
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
问题:github上不了,但是其他网页可以正常打开
github上不了,但是其他网页可以正常打开,试了关闭防火墙,dns刷新,都没用后,参考以下文章成功打开Github

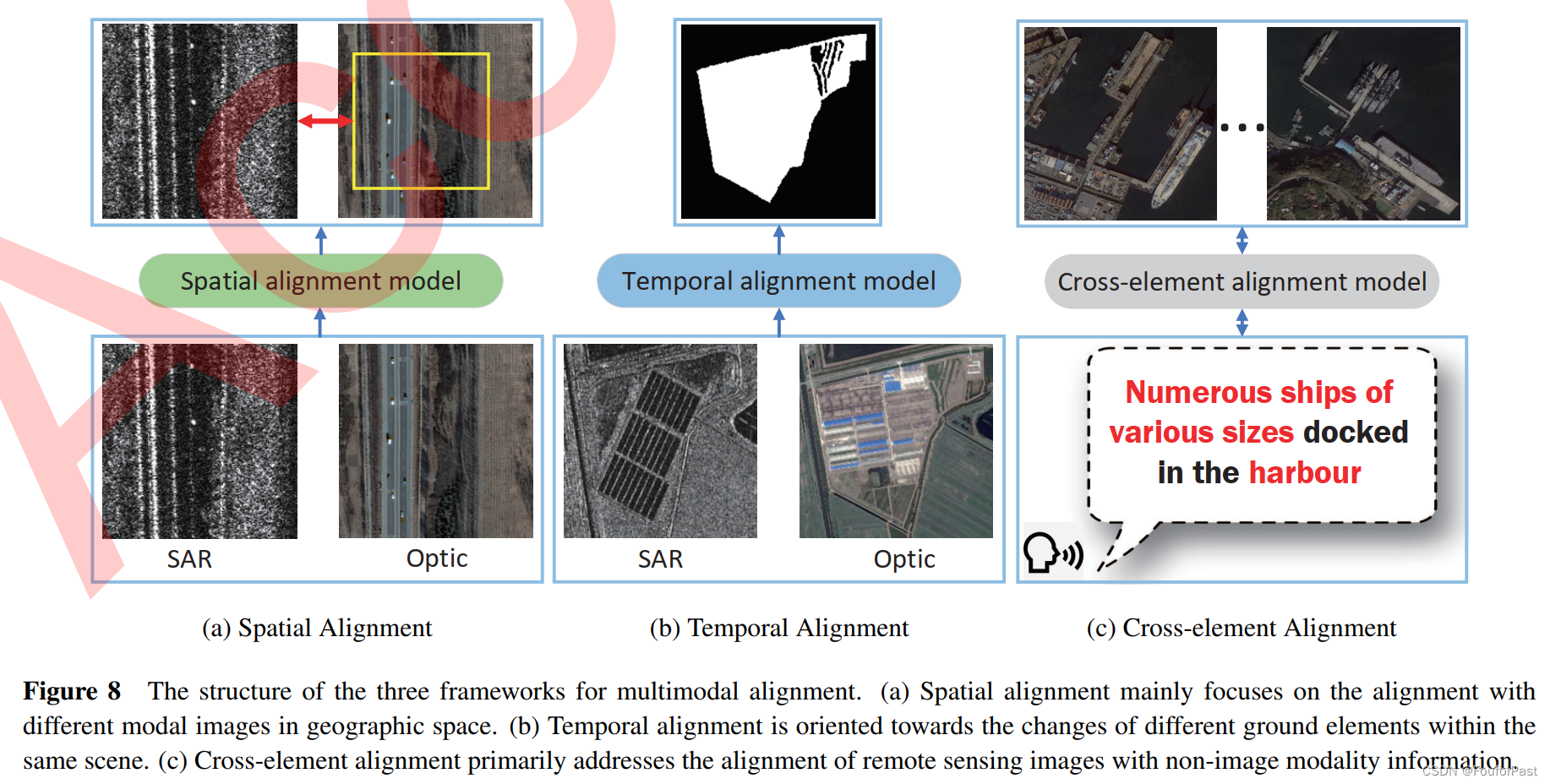
论文阅读:multimodal remote sensing survey 遥感多模态综述
从多模态表示,对齐,融合,跨模态转换,协同学习等5个大方面来介绍在遥感领域的分类和相关工作
transformer模型学习路线
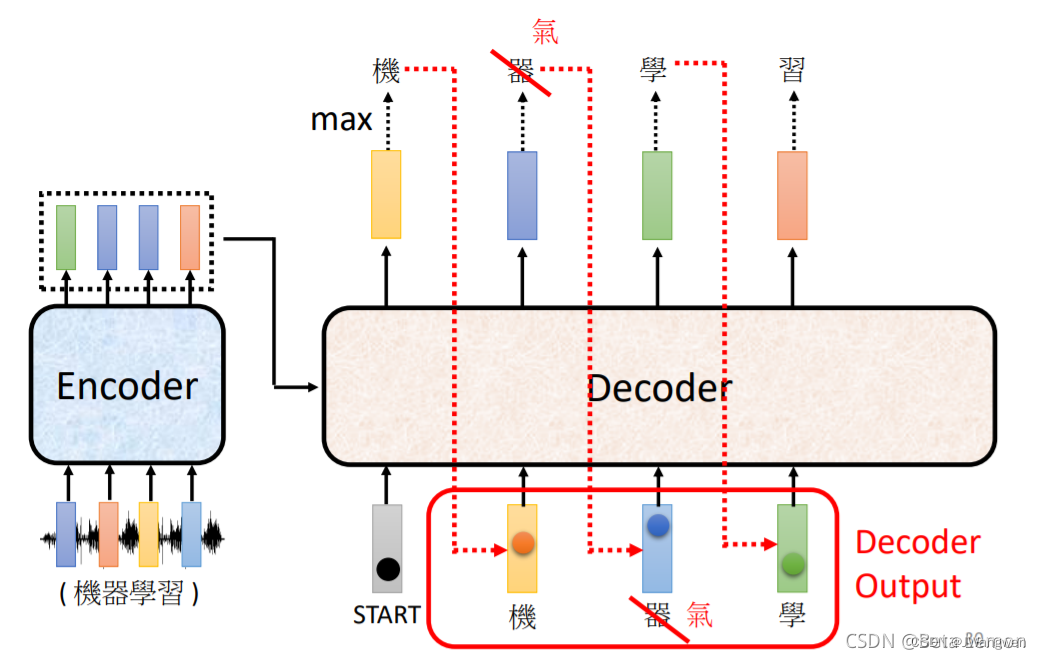
Transformer学习路线完全不懂transformer,最近小白来入门一下,下面就是本菜鸟学习路线。Transformer和CNN是两个分支!!因此要分开学习Transformer是一个Seq2seq模型,而Seq2seq模型用到了self-attention机制,而self-attention机制又在Encoder、Decode中。因此学习将从self-Attention->Seq2
论文阅读:multimodal remote sensing survey 遥感多模态综述
从多模态表示,对齐,融合,跨模态转换,协同学习等5个大方面来介绍在遥感领域的分类和相关工作
transformer模型学习路线
Transformer学习路线完全不懂transformer,最近小白来入门一下,下面就是本菜鸟学习路线。Transformer和CNN是两个分支!!因此要分开学习Transformer是一个Seq2seq模型,而Seq2seq模型用到了self-attention机制,而self-attention机制又在Encoder、Decode中。因此学习将从self-Attention->Seq2
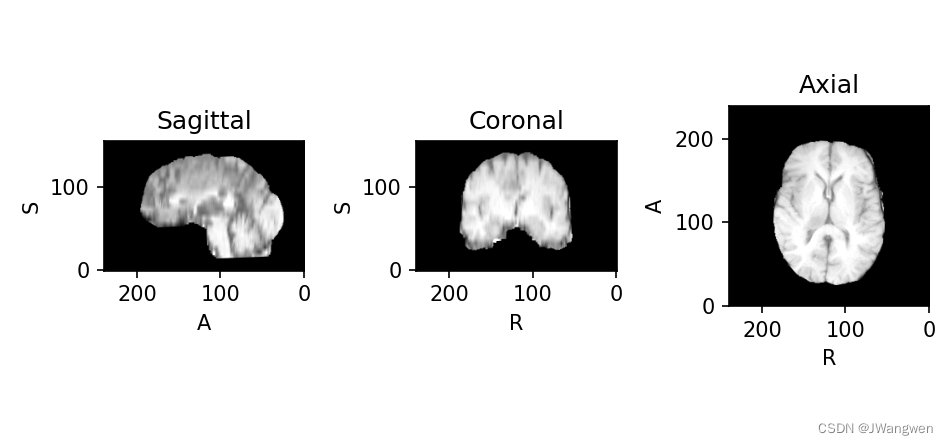
BraTs数据集处理及python读取.nii文件
BraTs数据集及python读取.nii文件医学文件
到底了