- @qq_36066039
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
flinkTable中的所有数据类型都是class封装的,在这之中有一个基类: org.apache.flink.table.types.DataType,所有的类型都是该类的实现类。除此之外Flinktable还提供了一个final类型的类,该类提供了大量的静态方法可以指定访问实现了 org.apache.flink.table.types.DataType接口的真正实现类, 这个final类型
createRemoteEnvironment(host: String, port: Int, jarFiles: String*)意思是将你本地的代码打的jar包,远程提交到已经存在的flink集群上.注意此程序再idea运行的时候,idea上不会有任何输出的.在这种模式下idea就是相当于一个传输所需jar文件的客户端,程序一旦执行之后,就和idea无关了.1.代码如下:package co
look up join 能做什么?不饶关子直接说答案, look up join 就是广播。重要是事情说三遍,广播。flinksql中的look up join 就类似于flinks flinkDatastream api中的广播的概念,但是又不完全相同,对于初次访问的数据会加入缓存, 一定时间未访问到的则会从缓存中去除。而广播则是直接广播到每个exxcotor.比如我们有一张订单表orders
注意find只能查找一个node,要想获得所有搜索结果可以用findAll(),用 ‘’/'分割搜索路径,'./ ’ 表示当前节点路径。

目录一:FileInputStream/FileOutputStream二:改进的复制功能。2.1需要注意的地方是一:FileInputStream/FileOutputStream首先一点计算机识别的都是二进制,所以来说,读取文件的第一步就是建立文件连接,然后构建字节流通道,java所有的I/O都是字节流开始的,所谓的字符流也是在字节流的基础上进行的字节流转化成字符流的...
用户: 道德经不就是很短的语句么,很多道理也都是共识吧,为社么能流传下来?这其中是否有不知的秘密AI: 你的观察非常敏锐。《道德经》确实只有五千余字,而且很多句子读起来像是“老生常谈”的常识(比如“柔弱胜刚强”、“知足不辱”)。但恰恰是这种“看似简单却难以做到”以及“看似常识却常被违背”的特质,构成了它流传两千多年的核心秘密。它不仅仅是一本哲学书,更像是一套“高维度的生存算法”和“反直觉的思维模型
Tensorflow 的cpu版本和gpu版本所谓的cpu版本gpu版本值得就是计算核心的分别,分别是gpu核心,cpu核心。既然如此了解cpu和就显得很重要了。cpu是一种复杂的计算的软硬件结合,是个繁琐的计算处理,包含了各种中断,资源切换等。gpu也是一种软硬件解和体系,他适合的是一种简单的重复的大量运算。而且他不想cpu就几个核,目前gpu核有五百多个,而且未来还会增加。两种...
概述很多学习python的初学者甚至学了有一段时间的人接触到anaconda或者其他虚拟环境工具时觉得无从下手, 其主要原因就是不明白这些工具究竟有什么用, 是用来做什么的, 为什么要这么做, 比如笔者一开始也是不明白为啥除了python之外我还需要这么一个东西, 他和python到底有啥联系和区别, 为啥能用来管理python.在使用过之后我才逐渐发现其实anaconda等环境管理工具究...
目录概要如果你不小心删除了系统的python怎么办一:误删怎么办?1.1:删除相关python1.2:删除相关yum1.3:安装系统python1.4:安装系统yum...

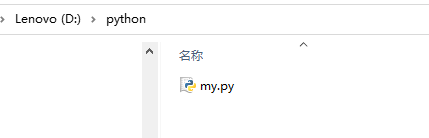
有时候我们需要在程序中导入额外的python包,这个时候就需要用到这里的知识.这里介绍两种导包方式.一. 手动导包其工作的原理就是将搜索路径加入python的sys.path 数组中.python工作的时候会自动搜索sys.path 中所有的目录,那么我们可以自定义一个目录,然后在目录中建立一个或者多个.py文件,然后将这个目录添加到sys.path中就行了,举例如下.建立目录: D:\pytho