




- @qq_33589510
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Java 25 新特性速览 Oracle正式发布Java 25,带来18项重要增强。新版本聚焦三大方向:提升开发效率、增强AI支持、优化性能安全。语言特性方面,模式匹配支持原始类型(JEP 507),模块导入简化(JEP 511),"Hello World"精简至3行(JEP 512),构造函数更灵活(JEP 513)。企业级支持方面,提供8年长期维护,确保业务平稳迁移。该版本
本文深入解析编程助手的工作原理,指出其核心在于LLM(语言模型)与工具使用的结合。当用户提出任务时,助手通过收集上下文、制定计划和执行操作三个步骤进行处理,其中关键是通过工具调用来实现与外部环境的交互。文章特别强调Claude系列模型在工具使用方面的卓越表现,使其能够处理复杂任务、具备平台扩展性和更高安全性。最终说明,正是这种工具使用能力将文本生成模型转变为真正实用的编程助手,使其能有效读取文件、
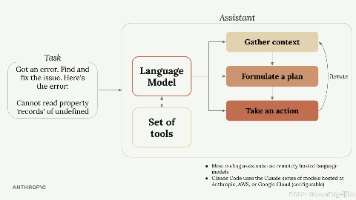
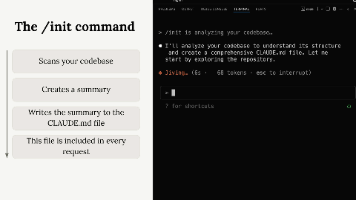
本文介绍了如何高效管理Claude AI在项目开发中的上下文交互。核心方法包括:1)使用/init命令初始化项目,生成CLAUDE.md配置文件;2)通过项目级、本地和全局三种配置文件定制Claude行为;3)利用@引用语法精准引入相关文件内容;4)在配置文件中添加自定义指令优化交互效果。这些技巧能帮助开发者减少无关信息干扰,提升AI协作效率,特别适用于处理大型代码库场景。
本文介绍了OpenClaw项目的安装与使用指南。主要内容包括:1)安装Node.js和pnpm等前提条件;2)克隆项目并安装依赖;3)启动网关服务;4)获取Dashboard访问链接;5)可选配置本地LM Studio模型;6)项目更新方法;7)总结操作流程图。该指南帮助用户快速搭建OpenClaw环境,通过简单命令即可完成从安装到访问控制界面的全过程,支持云端API和本地模型两种使用方式。
如果检测到疑似劫持行为的内容,它会在传递结果时附加警告,提醒模型对这些内容保持怀疑,并以用户的真实需求为准。但在自动模式下,会移除那些可能导致任意代码执行的宽泛规则(如通配的 shell 或脚本解释器调用),以确保分类器能看到潜在危险操作。:模型理解用户目标并试图帮忙,但采取了超出用户授权的行动,例如使用偶然发现的凭证或删除它认为“碍事”的内容。核心原则是评估操作的实际效果,而不是表面形式,并且默
个性化的系统提示词多轮对话记忆本文基于 LangChain,用不到 30 行代码复刻这两个能力,构建一个可自定义人格的对话 AI。步骤代码量核心组件定义模板~5 行配置记忆~1 行组装链~5 行LLMChain运行对话~1 行.predict()LLMChain = LLM + Prompt + Memory 的优雅封装组合而非重写。
点击下方“JavaEdge”,选择“设为星标”第一时间关注技术干货!免责声明~任何文章不要过度深思!万事万物都经不起审视,因为世上没有同样的成长环境,也没有同样的认知水平,更「没有适用于所有人的解决方案」;不要急着评判文章列出的观点,只需代入其中,适度审视一番自己即可,能「跳脱出来从外人的角度看看现在的自己处在什么样的阶段」才不为俗人。怎么想、怎么做,全在乎自己「不断实践中寻找适合自己的大道」1.
Claude Code与开源模型集成指南 本文介绍了如何将Claude Code编程助手与开源模型集成使用的最新方案。从Ollama v0.14.0开始支持Anthropic的Messages API,用户可以在本地或云端运行Claude Code。文章详细说明了安装配置步骤,包括环境变量设置、模型选择建议(推荐本地模型gpt-oss:20b和云端模型glm-4.7:cloud等),以及上下文长度
0相关源码1 k-平均算法(k-means clustering)概述1.1 回顾无监督学习◆ 分类、回归都属于监督学习◆ 无监督学习是不需要用户去指定标签的◆ 而我们看到的分类、回归算法都需要用户输入的训练数据集中给定一个个明确的y值1.2k-平均算法与无监督学习◆k-平均算法是无监督学习的一种◆ 它不需要人为指定一个因变量,即标签y ,而是由程序自己发现,给出类别y...
0相关源码1 朴素贝叶斯算法及原理概述1.1 朴素贝叶斯简介◆ 朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的一种分类方法◆ 朴素贝叶斯算法是一种基于联合概率分布的统计学习方法◆ 朴素贝叶斯算法实现简单,效果良好,是一种常用的机器学习方法1.2 贝叶斯定理◆ 朴素贝叶斯算法的一个基础是贝叶斯定理贝叶斯定理(英语:Bayes’ theorem)是[概率论]中的一个[定理],描...