
写文章




- @qq_32068809
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
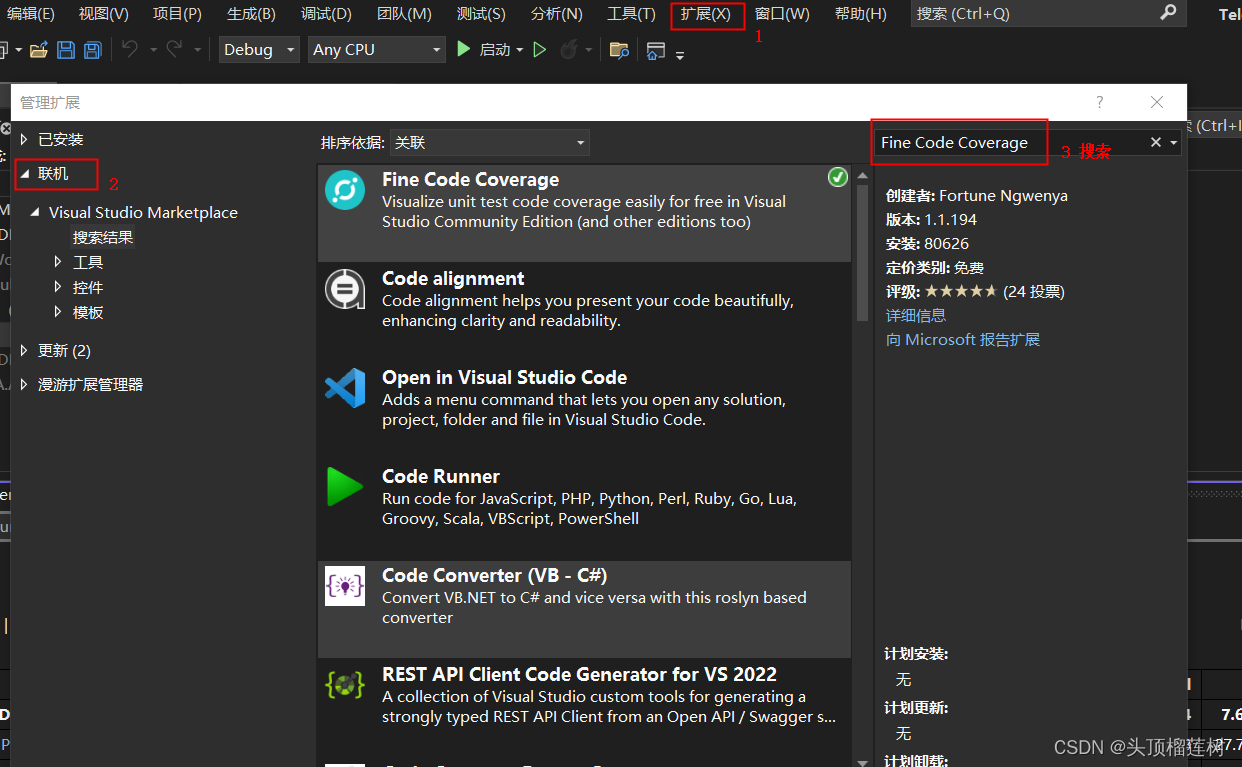
社区版Visual Studio通过安装开源插件Fine Code Coverage实现单元测试代码覆盖率统计
Fine Code Coverage 单元测试覆盖率
java连接phonix报错:KeeperErrorCode = NoNode for /hbase/hbaseid
我的phonix jdbc url连接参数值如下jdbc:phoenix:prod-bigdata-pc10:2181/hbase-unsecure可见我在url中已经指定了zk连接端口和hbase节点等信息,由于我是hdp环境,该环境的hbase在zk上建立的根节点为/hbase-unsecure,所以需要指定实际值,但是实际建立phonix连接时仍旧会到zk上找默认的/hbase节点,并且也发
kafka指定时间范围消费一批topic数据
public class JavaConsumerTool {/*** 创建消费者* @return*/public static KafkaConsumer<String, String> getConsumer(){Properties props = new Properties();props.put("bootstrap.servers", "127.0.0.1:9092")
到底了