




- @qq_24330181
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
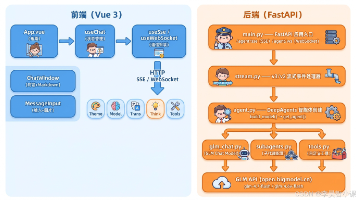
本教程将手把手教你从零开发一个完整的AI智能体应用,采用前后端分离架构。后端使用FastAPI+DeepAgents实现智能体功能,支持双模型切换(GLM-4.7-Flash和GLM-4.6V-Flash)、自定义工具、子代理委派等;前端采用Vue 3+Vite构建,实现SSE/WebSocket双通信模式、Markdown渲染、主题切换、图片上传等交互功能。教程分为四大部分:项目总览、后端实现、
本文提供了Claude Code命令行工具的完整安装、使用和管理指南。主要内容包括:1)三种安装方法(标准安装、国内镜像安装及解决脚本拦截的推荐方案);2)安装报错解析与两种解决方案;3)卸载方法;4)常用操作命令表;5)常见问题排查。重点解决了npm安全拦截导致的安装脚本被阻止问题,推荐使用临时允许脚本的方案,并提供了验证安装成功的方法。同时涵盖了版本更新、登录账号等日常操作,帮助用户顺利使用C
本文提供了Claude Code命令行工具的完整安装、使用和管理指南。主要内容包括:1)三种安装方法(标准安装、国内镜像安装及解决脚本拦截的推荐方案);2)安装报错解析与两种解决方案;3)卸载方法;4)常用操作命令表;5)常见问题排查。重点解决了npm安全拦截导致的安装脚本被阻止问题,推荐使用临时允许脚本的方案,并提供了验证安装成功的方法。同时涵盖了版本更新、登录账号等日常操作,帮助用户顺利使用C
本教程全面介绍PyArrow 24.0.0在Python 3.14环境中的使用,涵盖安装、核心概念、数据类型和基础操作。主要内容包括: 环境配置:提供PyArrow安装命令和版本校验方法,介绍核心模块导入方式。 核心概念:讲解Arrow Array、Table、Schema等基本数据结构,以及列式存储特点。 数据类型系统:详细说明基础类型(整型、浮点、字符串等)、复合类型(列表、结构体、字典)和字
# Python Requests 爬虫完全指南(增强版)本指南在原有基础上增加了处理JavaScript渲染页面、代理IP使用和高并发处理等高级内容,从基础到进阶全面覆盖爬虫开发所需知识和技巧。

本教程将带领你从基础到进阶,全面掌握Python 3.14的新特性和核心功能。

Optional 是 Java 8 引入的一个容器类,用于包装可能为 `null` 的对象。它的核心作用是**优雅地处理空值**,避免直接操作 `null` 导致的 `NullPointerException`,同时让代码意图更清晰。


- 使用普通用户(非 root)- 项目放在 `/opt/mock_server`- 使用 **Gunicorn** 作为 WSGI 服务器(比 Flask 内置服务器更稳定、支持并发)- systemd 服务文件完整配置

本教程系统介绍了Python操作Hive的4种主流方式,包含7个教学脚本和完整实践指南。教程基于hive-app/项目结构,涵盖PyHive原生SQL、pandas集成、SQLAlchemy引擎及PySpark两种数据源分析等核心内容,所有代码均逐行注释并经过验证。项目提供完整的虚拟环境配置、依赖清单、示例数据和spark-submit脚本,适合初学者从零搭建Hive分析环境。教程要求Python