




- @python12345678_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
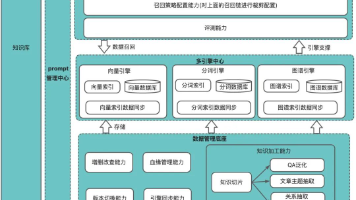
本文系统介绍了在Agentic AI技术快速发展的背景下,如何构建可靠、高效的AI Agent应用。文章重点阐述了提示词工程、工作流设计和知识库构建三大核心竞争力的实践方法。在提示词方面,详细讲解了系统提示词的构成要素和优化技巧;在工作流设计上,推荐使用DSL描述替代自然语言;在知识库构建环节,介绍了RAG技术和向量数据库的应用。通过实战案例和优化建议,本文为开发者提供了从零构建AI Agent的
本文分享了作者将多模态模型与RAG系统结合的实践经验,揭示了多模态应用远比理论复杂的真相。文章详细剖析了多模态模型在实际业务中的应用挑战,特别是不同模态数据间的关联关系处理和数据召回方式等关键问题。对于想要探索多模态RAG系统的开发者来说,本文提供了宝贵的实战经验和思考方向,帮助你少走弯路,更高效地实现多模态与RAG的融合应用。多模态与RAG的结合是一个应用的实践过程,其实际操作远比理论要复杂得多
随着ChatGPT的兴起,大语言模型再次走进人们的视野,其在NLP领域表现出的语言识别、理解以及推理能力令人惊叹。越来越多的行业开始探索大语言模型的应用,比如政务、医疗、交通、导购等行业。通义系列、GPT系列、LLama系列等模型,在语言交互场景下表现十分抢眼。以Gemini为代表这类大模型甚至发展出了视觉和听觉,朝着智能体的方向演化。他们在多个指标上展现的能力甚至已经超过了人类。
AI应用正迎来爆发期,对于小白和程序员而言,这是绝佳的学习风口和就业机遇。文章分析了AI应用爆发的两大核心催化因素,并详细介绍了AI应用的核心板块,包括AI营销、AI电商、AI视频/多模态、AI医疗和AI办公,每个板块都涵盖了核心逻辑、行业现状、市场规模和重点企业进展。此外,文章还探讨了如何学习大模型AI,提供了从零到一的AI学习路径图、大模型调优实战手册等实用资料,帮助读者在AI时代抢占先机。
本文是自己在学习LLM时,阅读《A Survey of Large Language Models》和其他相关材料时的笔记,力求对构建LLM涉及的主要环节有一个大颗粒度的全景感知,一些比较关键或者感兴趣的话题会附上一些推荐阅读的博客。希望能根据这篇博客,读者也能按图索骥式的去学习LLM。

就像西方不能没有耶路撒冷一样,我们也不能没有开源的 AI 模型。只要这个开源的小模型是免费的、够好用、够小,它就是个好模型。没错,就是 Llama3,相信大家都很熟悉了,羊驼家族的明星。首先我们需要进入Llama3的官方网站,下载一个软件,可以简单理解为启动器,看见这个可爱的羊驼,点击右上角的下载即可:下载好后直接双击安装即可。安装完毕后,点击运行弹窗,来到当前这个界面:如果不小心退出了,可以通过
此外,随着改进版Transformer架构(如Reformer、Longformer和Switch Transformer等)的出现,其在资源利用效率和处理超长序列的能力上得到了进一步优化和增强。Transformer组件详解:描述了Transformer的几个关键方面,如编码器包含六个包含自我注意力和前馈神经网络两层子层的块,而解码器同样包含六个块,但比编码器多一个用于处理编码器输出的多头注意力

本文以大语言模型中应用到的强化学习算法——PPO为核心,介绍了从基础强化学习算法(策略梯度、AC等)到PPO的发展路径、核心问题及解决思路,最后简介了PPO在InstructGPT的应用。希望本文可以启发更多NLP研究者将RL更多、更好的应用在NLP的模型和场景之中。

那天凌晨三点,我还在修复生产环境的bug。无意间打开了同事的代码,发现他用了近500行Python脚本来对接OpenAI API。天呐!这代码看起来像是用血泪写成的…我笑了。这不就是两年前的我吗?当初为了实现一个简单的AI问答功能,写了一堆繁琐的token处理、上下文管理和错误重试逻辑。如今有了,这些痛苦完全可以避免。LangChain到底是什么?它是构建LLM应用的"乐高积木"。Harrison
随着人工智能技术的不断发展,大模型已经成为了人工智能领域的重要组成部分。然而,随着模型规模的扩大,安全问题也成为了我们需要关注的重要方面之一。在本文中,我们将探讨大模型的安全问题,并提供一些解决方案。大模型的安全问题主要包括以下几个方面:数据安全:大模型需要大量的训练数据,这些数据可能包含敏感信息。如果这些数据被泄露,可能会导致严重后果。模型安全:大模型可能会被攻击者利用,进行恶意操作,如生成恶意