




- @maizeman126
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
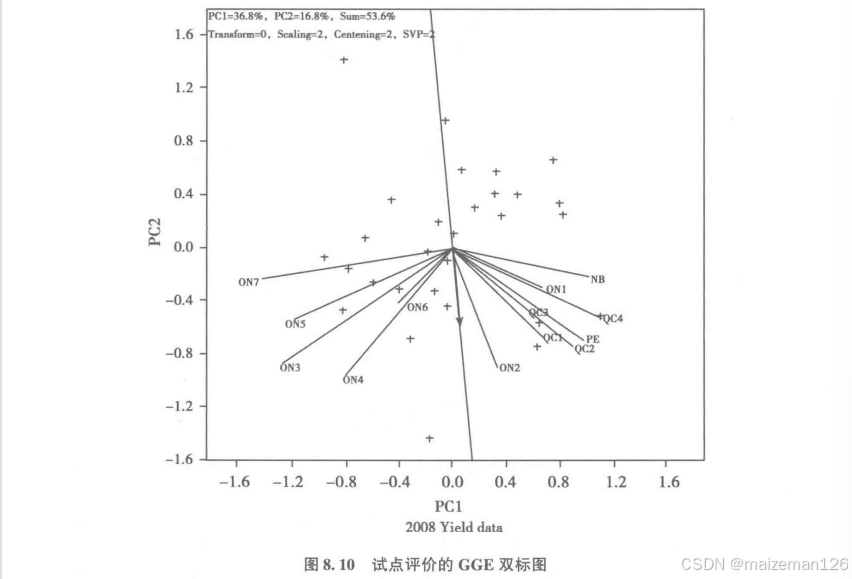
再次,即使是合适的试点在品种试验中也可能存在冗余的问题,多余的试点增加试验成本,却不能增加关于基因型的信息。在基于SD定标和h加权数据的GGE双标图中,试点向量的长度近似于试点的遗传力平方根。因此,GGE双标图中的试点向量长度可以表示试点的h或其与其他试点相关性的强度。品种生态区内的试点都是正相关,如图试点间的锐角所示,可见试点对其所在品种生态区的代表性很好。基于SD定标和h加权数据的GGE双标图
使用range函数时,用逗号把起始值、结束值和步长隔开,而在切片语法中使用冒号来分隔。range函数可用于创建生成器并转换成一个值列表,但切片的冒号语法仅做切片和取子值时才有意义,它本身没有内在意义。pandas的DataFrame对象和其他语言(比如R)中的DataFrame对象相似,每列的类型必须相同,而每行可以包含混合类型。在当前的示例中,iloc和loc的行为完全相同,因为索引标签就是行号

本例中籽粒产量的GGE双标图仅解释了G和GE总变异的53.6%,说明籽粒产量的GE/G比率更大,GE的构成也更为复杂。下图就是“谁赢在哪里双标图”,与前一个功能图相比,仅仅是去掉了试点向量,而增加了多边形和从原点到多边形各边的垂线。下面这张图标有8.5的双标图与上面那个标有8.4的双标图是相同,只是图8.5采用了基因型聚焦的奇异值分析方法。GGE双标图“谁赢在哪里”功能图确实解释了示例中可能包括一

本例中籽粒产量的GGE双标图仅解释了G和GE总变异的53.6%,说明籽粒产量的GE/G比率更大,GE的构成也更为复杂。下图就是“谁赢在哪里双标图”,与前一个功能图相比,仅仅是去掉了试点向量,而增加了多边形和从原点到多边形各边的垂线。下面这张图标有8.5的双标图与上面那个标有8.4的双标图是相同,只是图8.5采用了基因型聚焦的奇异值分析方法。GGE双标图“谁赢在哪里”功能图确实解释了示例中可能包括一
对于分类变量的解释必须和参考变量(即从分析中删除的虚拟变量)联系起来。在尝试解释sklearn模型时,一个棘手的问题就是模型的系数不带标签,原因是numpy ndarray无法存储这类元数据。线性回归的目标是描述响应变量(或“因变量”)和预测变量(也称“特征”、“协变量”、“自变量”)之间的直线关系。对分类变量建模时,必须创建虚拟变量,即分类中的每个唯一值都变成了新的二元特征。在sklearn中,

使用range函数时,用逗号把起始值、结束值和步长隔开,而在切片语法中使用冒号来分隔。range函数可用于创建生成器并转换成一个值列表,但切片的冒号语法仅做切片和取子值时才有意义,它本身没有内在意义。pandas的DataFrame对象和其他语言(比如R)中的DataFrame对象相似,每列的类型必须相同,而每行可以包含混合类型。在当前的示例中,iloc和loc的行为完全相同,因为索引标签就是行号
在左侧的资源中找到需要请求的网页,单击需要请求的网页,在heades(标头)中可以看到requests headers(请求标头)的详细信息。除了GET请求外,有时还需要发送一些编码为表单的形式的数据,如在登录的时候请求就位post,因为如果用get请求,密码就行显示在URL中,这个非常不安全。在网络爬虫中,静态网页的数据比较容易获取,因为所有数据都呈现在网页的HTML代码中。requests并不

这样在品种生态区内基因型的差异就更明显。选择广适性的高产品种是育种的理想目标,但在存在这样的情形,即在GE效应很大并由明显品种生态区分化时,这样的目标很难实现。本例中基因型的GGE距离与它们到AEA轴的投影是高度相关的(r=0.93),说明基因型主效是GGE距离主要决定因子,只是因为品种的稳定性存在差异,二者之间才不完全相关。2008年在该生态区最好(产量最高)的品种是“Sylva”、“1234-

(1)data=None,就是数据源。(2)x=None, y=None,如果不指定x和y,则以整列数据绘制一个小提琴;如果制定了x和y,则会按照分类型数据对数值型数据进行分组,来绘制小提琴。
表2为回归系数的t检验分析结果,可见intercept(截距)和temp(temp列的回归系数)均达到极显著水平,且temp回归系数大于0。Dep.Variable:响应变量的名称,Dep为Depended的缩写。Df Residuals:残差自由度,样本容量减去参与估计的参数个数。由散点图可以看出啤酒(beer)的销量与温度(temp)有正相关的关系。Prob(F-statistc):F统计量对