- @m0_74191152
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细讲解了 FastAPI 中的响应系统,重点区分了 response_class 和 response_model 的不同用途: response_class 控制 HTTP 响应类型(如 HTML/JSON/文件),决定客户端如何解析响应 response_model 控制 JSON 数据结构,用于字段过滤和格式验证 介绍了默认 JSON 响应、文件响应和 HTML 响应的实现方式 解释了

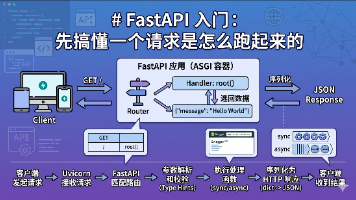
本文解析了FastAPI框架的核心工作原理,帮助开发者理解请求-响应链路的关键环节。文章指出学习FastAPI的难点不在于语法,而在于理解从Python函数到HTTP响应的完整转换过程。主要内容包括: 最小FastAPI应用的构成,重点解析@app.get()装饰器建立URL与函数的映射关系 自动序列化机制:Python对象如何自动转为JSON响应 API文档自动生成原理,基于路由信息和类型注解
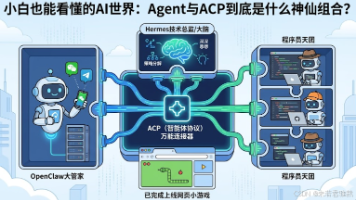
本文科普了AI Agent(智能体)与ACP(智能体通信协议)的核心概念。Agent是能自主干活的“超级打工人”,ACP则是连接不同AI的“通用翻译器”。在多Agent实战中,OpenClaw作为项目经理负责执行与统筹;Hermes作为技术总监负责任务拆解与自我进化;它们通过ACP协议,将编程任务无缝派发给Claude Code、OpenCode和Codex组成的程序员天团。借助ACP,原本孤立的
AnySearch Skill 是一个面向AI Agent的搜索适配层,提供智能化的联网检索能力。它通过SKILL.md定义搜索决策流程,支持跨平台CLI调用,将请求路由到云端JSON-RPC接口。核心功能包括:通用网页搜索、垂直领域搜索(金融/学术/法律等)、批量并行查询和网页正文抽取。相比直接调用搜索引擎,它提供了更结构化的搜索流程,适合需要"普通搜索+垂直数据+页面抽取+多查询并行"的场景。

集中日志平台解决了多服务场景下日志分散、检索低效等问题。ELK(Elasticsearch、Logstash、Kibana)是主流方案,Filebeat负责轻量采集,Logstash处理复杂解析,Elasticsearch存储检索,Kibana提供可视化。日志应结构化输出(如JSON),包含关键字段(如traceId、时间戳、业务ID),便于关联分析和问题定位。实际部署中,可根据需求选择Fileb

Java类加载器负责将.class字节码加载到JVM中,采用双亲委派模型确保核心类优先由上层加载器加载,避免重复加载和API篡改。类加载过程分为加载、验证、准备、解析、初始化等阶段,其中准备阶段为静态变量分配内存并设默认值,初始化阶段执行显式赋值和静态代码块。特殊场景(如JDBC SPI、Tomcat容器)会打破双亲委派,通过线程上下文类加载器或自定义加载器实现隔离加载。类初始化触发条件包括new
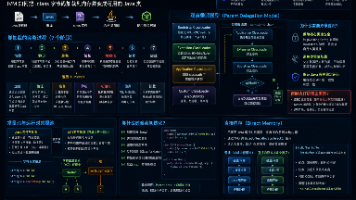
AnySearch Skill 是一个面向AI Agent的搜索适配层,提供智能化的联网检索能力。它通过SKILL.md定义搜索决策流程,支持跨平台CLI调用,将请求路由到云端JSON-RPC接口。核心功能包括:通用网页搜索、垂直领域搜索(金融/学术/法律等)、批量并行查询和网页正文抽取。相比直接调用搜索引擎,它提供了更结构化的搜索流程,适合需要"普通搜索+垂直数据+页面抽取+多查询并行"的场景。
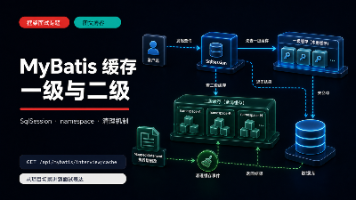
MyBatis缓存面试要点:一级缓存是SqlSession级别的本地缓存,默认开启,相同查询在同一个SqlSession内可能命中;二级缓存是namespace级别,需手动开启,可跨会话共享。关键要理解缓存作用域、命中条件(相同查询)、失效时机(增删改操作会清空对应作用域缓存)。二级缓存需谨慎使用,因多Mapper操作同一数据时难以保证一致性,且分布式环境下本地缓存无法跨节点同步。实际项目中,一级
索引优化实战指南:从设计到失效分析 摘要: 本文系统讲解了索引优化的核心要点,包括索引设计原则、联合索引使用技巧和常见失效场景分析。重点指出索引优化的本质是减少数据扫描量,提高查询效率。文章提供了实用的索引设计检查清单,详细解析了联合索引的最左前缀原则,并通过流程图直观展示了索引失效的排查路径。同时针对深分页性能问题,提出了覆盖索引结合子查询的优化方案。最后强调通过EXPLAIN验证执行计划的重要

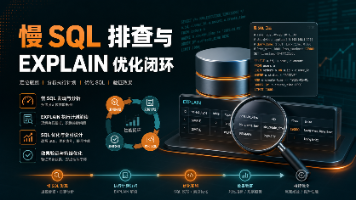
本文介绍了排查和优化慢SQL的完整闭环流程:首先通过链路追踪确认数据库瓶颈,再借助慢查询日志定位具体SQL,然后使用EXPLAIN分析执行计划,重点关注索引使用、扫描方式和额外成本。常见优化手段包括合理设计表结构、避免索引失效、减少回表操作、优化多表连接顺序等。文章强调SQL优化需要系统性思维,不能仅靠"加索引"解决,而应形成"监控发现问题→定位SQL→分析原因→针对