




- @m0_71832273
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你可以为你的集群购买 RTX GPU:66% 的 8路RTX 4080 和 33% 的 8路RTX 4090(要确保能有效地冷却)。如果解决不了 RTX 4090 的冷却问题,那么可以购买 33% 的 RTX 6000 GPU 或 8路Tesla A100。任何专业绘图显卡(如Quadro 卡);进一步学习,卖掉你的 RTX 4070,并购买多路RTX 4090。根据下一步选择的领域(初创公司

它采用了先进的Ampere微架构,具备强大的浮点运算能力和高效的内存带宽,能够满足大模型训练推理的高计算需求。对于预算有限的用户,可以选择性价比较高的V100 32G或A800/H800等型号的GPU。对于大模型而言,足够的显存能够确保训练过程的顺利进行。这些GPU不仅能够满足大模型的训练需求,还能够在推理过程中提供稳定可靠的性能。此外,还需要考虑GPU的散热性能,以确保在高负载运行时能够保持稳定
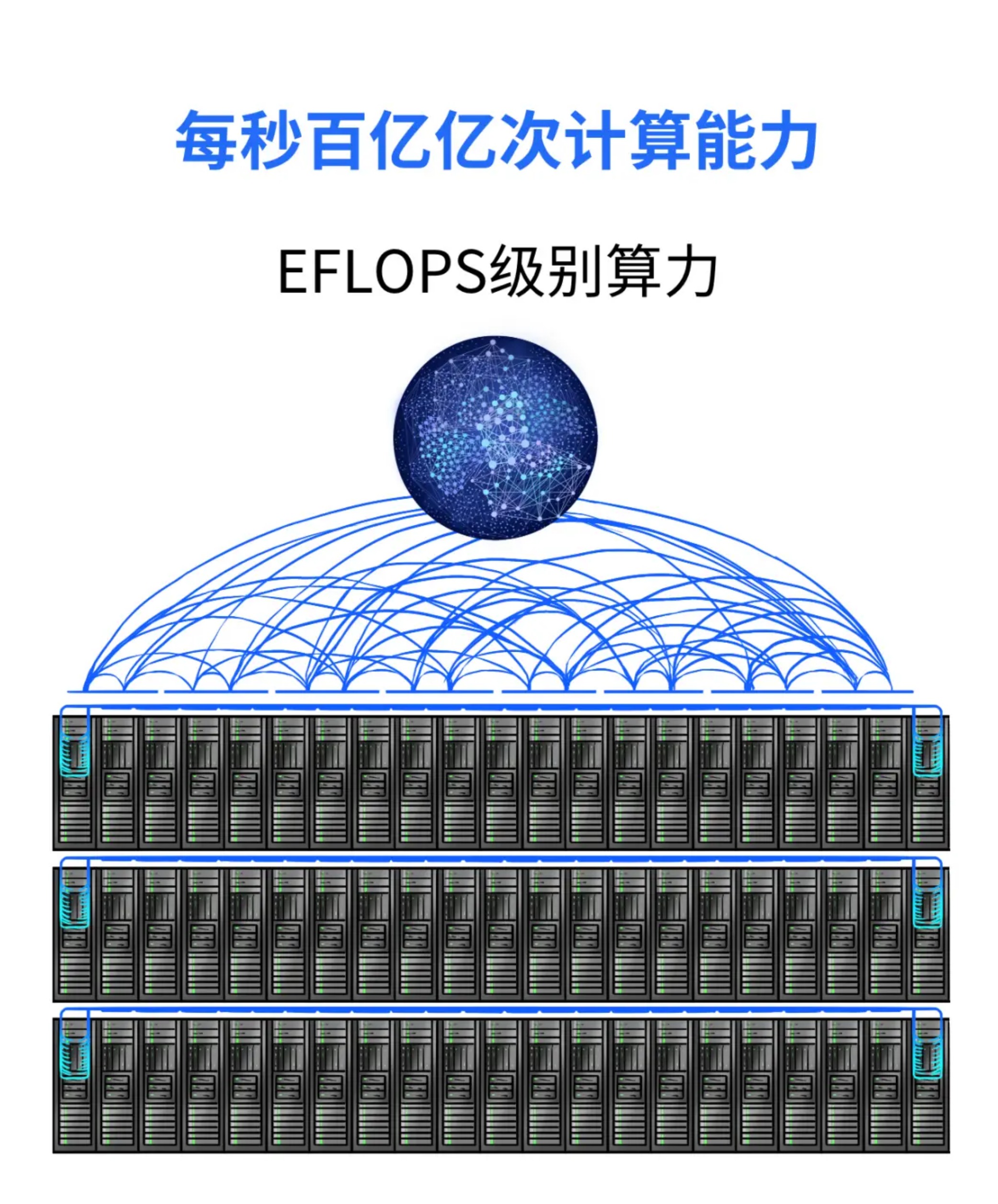
而集群的最大优势在于对故障服务器的监控是基于应用的,也就是说,只要服务器的应用停止运行,其它的相关服务器就会接管这个应用,而不必理会应用停止运行的原因是什么。高性能计算、深度学习集群服务器解决方案,提供标准的软硬件接口,支持分布式AI运算,可用于机器学习、人工智能和大数据开发等,相对传统的集群服务器,拥有低功耗、高可管理性、高灵活性等特点。集群系统可解决所有的服务器硬件故障,当某一台服务器出现任何
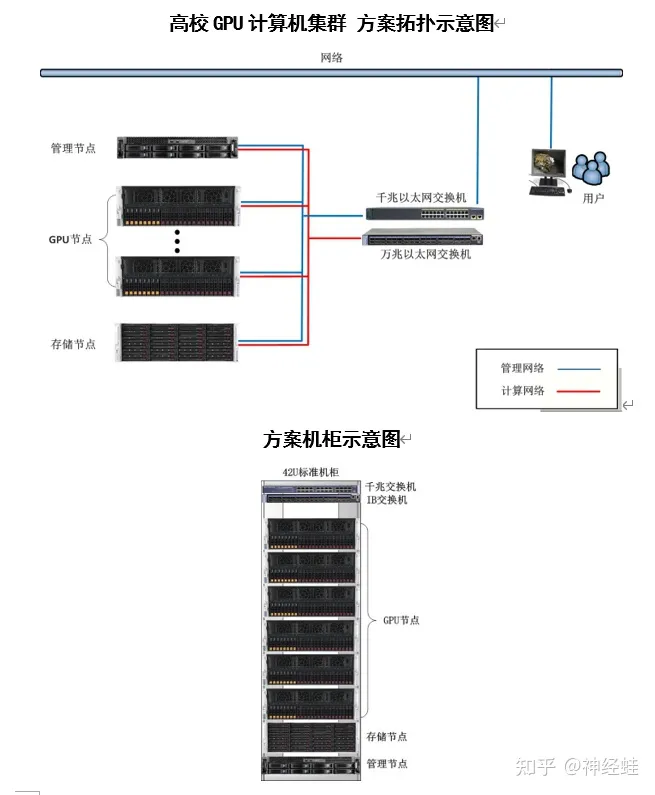
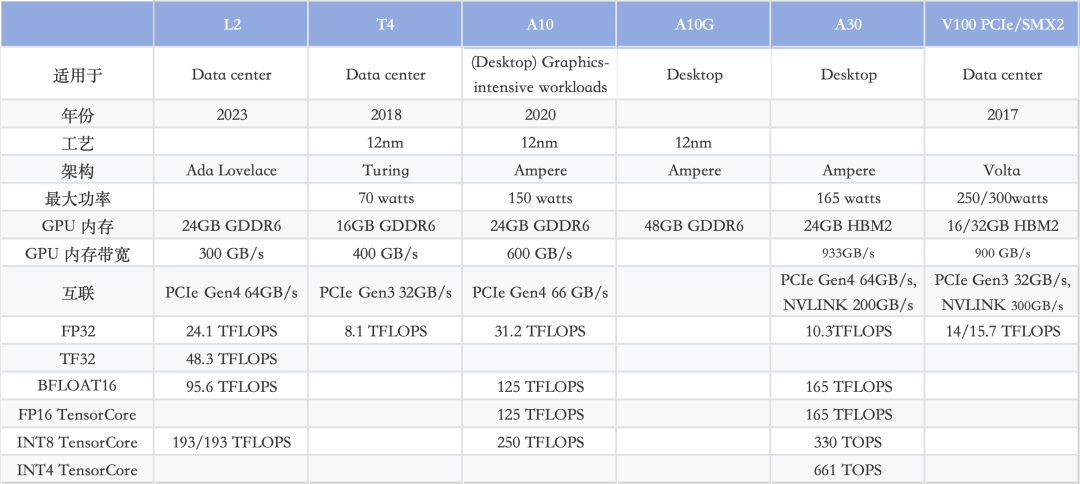
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);和华为/海思主流 GPU 的型号性能,供个人参考使用,文中使用数据均源自官网。本文转自SDNLAB,编译自arthurchiao的博客,主要介绍了。以上内容来自架构师联盟。
摘要:2026年内存价格持续上涨,主要因AI服务器抢占产能导致消费级存储芯片供应紧张。尽管短期出现现货价格回调,但上游合约价仍攀升,预计涨价趋势将持续至2028年。建议消费者:刚需用户选择次旗舰机型或老款库存机;非刚需用户延长旧设备使用周期;DIY玩家避免板载内存,考虑国产替代方案。理性消费、降低存储需求执念是应对当前涨价潮的有效策略。

在HPC性能卓越计算中还必须依据精密度来挑选,例如有的性能卓越计算必须双精度,这时候假如应用RTX4090或是RTX A6000就不适合,只有应用H100或是A100;另外也会对显存容量有要求,例如石油或石化勘查类的计算运用对显卡内存要求较为高;还有一些对系统总线规范有要求,因而。下面推荐几款深度学习服务器。

多数不用考虑GPU,但对CPU要求高,内存要求大,建议高核,大内存,如果追求性价比的话,可以选AMD的CPU。等主要强调GPU运算能力,存储空间要求往往很大,可以配置多块大空间硬盘,系统盘用SSD、存储用机械盘。,塔式比较安静,如果用GPU运算受卡数限制,4卡以内可以,液冷更静音。40系列相对性价比高,运算能力也不弱;:单双精度计算要求、显存、价格,,电源瓦数大于总功耗30%为宜;,空间大对散热有

适用于深度学习的GPU服务器配置过程中,大家一定会在市场上进行对比,往往会发现差不多的参数配置,甚至更高的参数配置价格会更低,这是怎么一回事呢?关于这个 问题,今天给大家举个例子,现在市场上有不少组装商家,为了赢得与客户的合作,往往会用客户满意的参数去吸引客户,殊不知参数并不能代表性能,而是性能的假象,这两天看到一个配置和大家分享一下:CPU:Intel Xeon **6148** 2.4 GHz

它采用了先进的Ampere微架构,具备强大的浮点运算能力和高效的内存带宽,能够满足大模型训练推理的高计算需求。对于预算有限的用户,可以选择性价比较高的V100 32G或A800/H800等型号的GPU。对于大模型而言,足够的显存能够确保训练过程的顺利进行。这些GPU不仅能够满足大模型的训练需求,还能够在推理过程中提供稳定可靠的性能。此外,还需要考虑GPU的散热性能,以确保在高负载运行时能够保持稳定
而集群的最大优势在于对故障服务器的监控是基于应用的,也就是说,只要服务器的应用停止运行,其它的相关服务器就会接管这个应用,而不必理会应用停止运行的原因是什么。高性能计算、深度学习集群服务器解决方案,提供标准的软硬件接口,支持分布式AI运算,可用于机器学习、人工智能和大数据开发等,相对传统的集群服务器,拥有低功耗、高可管理性、高灵活性等特点。集群系统可解决所有的服务器硬件故障,当某一台服务器出现任何