- @m0_71746299
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了Agentic AI与AI Agent的区别,阐述了Agentic Enterprise(智能体型企业)的概念及其核心价值。文章指出,2026年企业AI发展的关键条件已成熟,并提供了企业落地Agentic AI的路线图和治理建议。内容涵盖概念厘清、企业演进地平线、实施方法论、治理原则及行业监管动态,旨在帮助读者理解并把握Agentic AI带来的机遇。
随着技术发展,创建AI Agent的方法已演变为成熟的生态体系。文章介绍了四种主流创建方式:无代码/低代码配置平台(适合快速验证与业务落地,如OpenAI GPTs、Microsoft Copilot Studio、Dify等)、代码优先的开源开发框架(适合深度嵌入系统,如LangGraph、CrewAI)、云原生与大模型厂商官方SDK(适合垂直生态绑定,如OpenAI Agents SDK、Go
随着技术发展,创建AI Agent的方法已演变为成熟的生态体系。文章介绍了四种主流创建方式:无代码/低代码配置平台(适合快速验证与业务落地,如OpenAI GPTs、Microsoft Copilot Studio、Dify等)、代码优先的开源开发框架(适合深度嵌入系统,如LangGraph、CrewAI)、云原生与大模型厂商官方SDK(适合垂直生态绑定,如OpenAI Agents SDK、Go
本文介绍了Agentic AI与AI Agent的区别,阐述了Agentic Enterprise(智能体型企业)的概念及其核心价值。文章指出,2026年企业AI发展的关键条件已成熟,并提供了企业落地Agentic AI的路线图和治理建议。内容涵盖概念厘清、企业演进地平线、实施方法论、治理原则及行业监管动态,旨在帮助读者理解并把握Agentic AI带来的机遇。
本文介绍了Agentic AI与AI Agent的区别,阐述了Agentic Enterprise(智能体型企业)的概念及其核心价值。文章指出,2026年企业AI发展的关键条件已成熟,并提供了企业落地Agentic AI的路线图和治理建议。内容涵盖概念厘清、企业演进地平线、实施方法论、治理原则及行业监管动态,旨在帮助读者理解并把握Agentic AI带来的机遇。
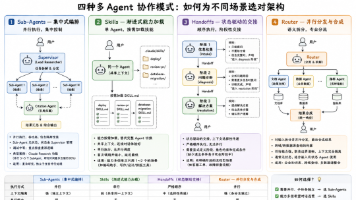
本文深入探讨了Sub-Agent到Multi-Agent的演进路径,重点解析了四种核心架构模式:集中式编排的Sub-Agents、渐进式能力加载的Skills、状态驱动的交接Handoffs以及并行分发与合成的Router。文章强调,选择架构模式应根据实际需求,避免盲目堆砌复杂度,并提供了决策树帮助读者判断。同时,还分享了多Agent系统在生产环境中的常见挑战和应对策略,如状态复杂性、非确定性调试
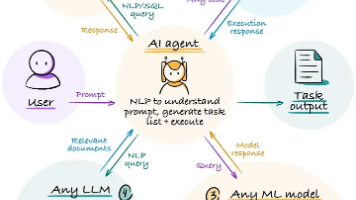
本文阐述了ChatGPT与大模型智能体(Agent)的区别,Agent不仅能对话,还能自主完成任务。通过“感知—规划—行动”循环,Agent能自主调用工具、执行操作并持续优化。Agent由大语言模型、工具、记忆和规划组成,已在编程、研究、办公等领域展现应用潜力。尽管面临错误风险和成本问题,Agent代表了AI从“会说话的大脑”向“能做事的帮手”的进化,是大模型公司2024年后的重点布局方向。
本文阐述了ChatGPT与大模型智能体(Agent)的区别,Agent不仅能对话,还能自主完成任务。通过“感知—规划—行动”循环,Agent能自主调用工具、执行操作并持续优化。Agent由大语言模型、工具、记忆和规划组成,已在编程、研究、办公等领域展现应用潜力。尽管面临错误风险和成本问题,Agent代表了AI从“会说话的大脑”向“能做事的帮手”的进化,是大模型公司2024年后的重点布局方向。
本文详细解析了大模型训练的四个关键阶段:预训练、微调、指令微调和RLHF,通过生动的比喻帮助读者理解每个阶段的目标、数据形态和期望行为。预训练是打基础,让模型学会语言规律和通用知识;微调是定向强化,使模型更擅长特定领域或任务;指令微调是教会交互,让模型按人类指令完成任务;RLHF则是偏好对齐,确保模型输出更符合人类偏好。文章强调这些阶段并非替代关系,而是常按顺序组合使用,以塑造出从“学会续写”到“
AI智能体架构设计的12条核心原则 智能体的核心在于自然语言与结构化工具的交互,通过Prompt引导LLM生成JSON指令,Switch语句解析决策,循环累积上下文直至任务完成。设计原则包括:自然语言转工具调用、自主掌控提示词与上下文、简化工具设计(JSON输出触发代码执行)、统一执行与业务状态、轻量API管理生命周期、人机协同工具调用、灵活控制流、错误压缩自修复、小型化功能聚焦、支持多入口触发响