




- @m0_60792028
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
b不要按个人感受去提改进建议,因为可能商业模式不是你理解的那样,这就需要提前去检索它的商业模式(搞清规模体量、用户特征、发展阶段、竞争格局、竞对的优劣势、当下业务策略以及方向)以及,针对异常出现的严重性,评估异常对业务的影响程度。Hypo该星巴克门店的营业时间为12小时(取整),忙时4h,闲时8h,制作一杯饮料时长3min,一小时最大生产量60/3*2=40杯(两台机器)6.考虑实践,分类讨论给结

我们挑选n_estimators\ 几棵树、\ min_samples_leaf\ 、\ min_samples_split\ 、\ max_depth\ 和\ max_features\ 每次进行特征选择时所纳入考虑的最大特征数 这几个进行参数搜索。corr.append(abs(train[[fea, 'target']].fillna(0).corr().values[0][1])) #从内

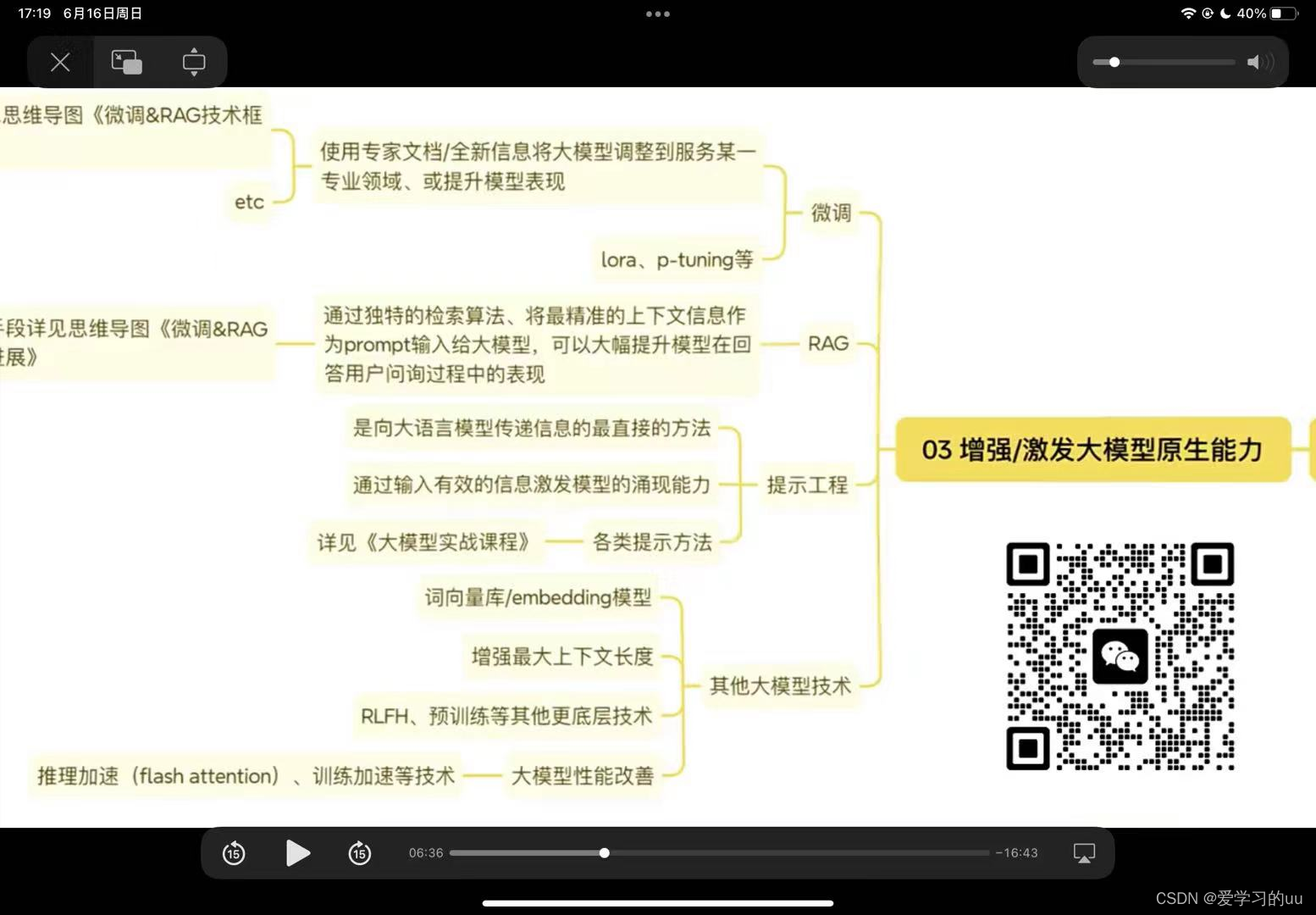
其中,tools告知模型可以用哪些参数,tool_choice告知模型是否可以用tools,一般设置为auto。解决方法:autogpt项目:调用外部工具解决,由此衍生出ai agent:能接入外部工具的ai。model=\ glm-4\ ,# 填写需要调用的模型名称。两个研究方向:开发特定的agents/强化大模型在某个领域的能力,后一个的大致方法如下图。参数的写法如上图所示,需要三个变量。前面
5.现在有ask和agent两种模式,对应老版本的chat和composer,因此简单功能用chat,复杂的用composer。检测(如何确认修改是想要的)(用save all先保存,再去查看效果,如果效果好就accept all)3.光标预测:比如你在一个注释前加了1.,再到第二条注释前会自动有2.,此时按TAB即可。总结:先chat后,需求拆解,给composer,并把问题记录下来,再问cha
Class_weight:输入{0:1,1:3}则代表1类样本的每条数据在计算损失函数时都会*3,当输入balanced,则调整为真实样本比例的反比,以达到平衡,但实际情况中不常用。#UI多迭代10的6次方次,tol是优化算法的收敛容忍度,c是正则化项参数。pl1.fit(x_train,y_train)#直接fit会报错,要改变求解器为saga。score_l1#打印发现degree=3是最优解

Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='你好!\\n', role='assistant', function_call=None, tool_calls=None))在代码环境中,ollama则提供了openai API风格的大模型调用方法。{'role
GLM4的原理与应用(用大模型做游戏npc制作)
而大模型微调又分为全量微调和高效微调两种,所谓全量微调,指的是调整大模型的全部参数,而高效微调,则指的是调整大模型的部分参数,目前常用的高效微调方法包括LoRA、QLoRA、p-Tunning、Prefix-tunning等。这是模型保存和检查点创建的频率,允许你在训练过程中定期保存模型的状态,--model_name_or_path /mnt/workspace/.cache/modelscop
接下来,定义大模型交互逻辑接口。首先需要明确,需要执行操作的过程是:大模型识别到用户的意图中需要调用工具,那么其停留的阶段一定是在 Action:xxxx : xxxx 阶段,其中第一个 xxx,就是调用的函数名称,第二个 xxxx,就是调用第一个 xxxx 函数时,需要传递的参数。就目前的AI Agent 现状而言,流行的代理框架都有内置的 ReAct 代理,比如Langchain、LlamaI
*在这一事件中,增量更新的是大模型输出的参数`arguments`,这个参数中的内容是用于执行外部函数的,而非对“北京现在的天气怎么样?正如我们在上节课中介绍的,使用.beta.threads.runs.submit_tool_outputs方法用于提交外部工具的输出,此方法也支持流媒体输出,如果在这个阶段需要开启流媒体传输,我们就需要使用 stream=True 参数来明确指定。为了使第二个`R