- @m0_59475014
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
幽灵容器现象本质上是Docker 内存状态、磁盘元数据目录与内核挂载点三者之间失去同步导致的“逻辑死锁”。如果容器频繁进行大量的 IO 操作(比如写日志、写传感器数据),而刚好遇到一次意外断电或系统 OOM(内存溢出),文件系统的 Journal(日志) 可能会损坏。
坑解决方案ET 模式只读一次,剩下数据再也收不到必须= EAGAIN)循环读空ET 模式用阻塞 fd 卡死ET 必须配合O_NONBLOCKeventfd 写完不读,CPU 100% 空转里必须 read 清空计数器close(fd)后忘记一般 close 自动移除,但 fd 被 dup 过时需要手动删信号中断导致epoll_wait返回 -1检查后 continue多线程同时操作同一个 epol
在应用层数据传输前,底层必须建立通信链路。DDS 使用 RTPS 规范中的简单发现协议 (SDP, Simple Discovery Protocol),该阶段独立于用户数据流。ROS2 的通信体系构建于 DDS (Data Distribution Service) 标准之上。其整体架构自上而下呈现严格的层级划分,每一层仅与相邻层交互。自主导航系统中,激光雷达节点 () 以 10Hz 频率发布。
在python工程下的文件夹,如果它直接包含了__init__.py,那它就会被认为是一个 python包无论对于多少级的子文件夹,这一条都生效。
本文介绍了使用CMake构建C++项目的完整流程,通过五个核心阶段解决实际问题:1)定义项目基本信息;2)查找依赖项路径;3)生成编译目标;4)配置编译链接选项;5)处理运行时依赖和安装分发。文章以使用ZeroMQ库为例,详细说明如何解决头文件找不到、链接失败、运行时库缺失等问题,并给出项目组织建议。最后总结了CMakeLists的典型编写顺序,强调这些是惯例而非绝对规则,推荐根据实际需求灵活调整
ROS 2 的 Python 节点不会像 C++ 一样编译成二进制程序。安装 package注册 ros2 run 入口安装 package.xml、resource、launch、config 等元信息生成 install/setup.bash 对应的环境信息安装 + 注册不是传统意义上的编译。Python 节点本身不编译成二进制。colcon build 负责安装和注册 Python pack
在 ROS2 中,主流的 Launch 文件是用Python编写的要一次性拉起多个功能包中的多个节点,最标准的做法是创建一个专门的启动功能包(通常命名为,在这个包里集中管理所有的 Launch 文件和参数配置。
在调用系统底层网络原语时,宏定义(在Python中以模块级常量的形式存在)决定了文件描述符的物理行为。以下是标准接口及其关键入参宏定义的对应关系。: 申请分配资源。family(地址簇): 决定网络层路由方式。: IPv4网络通信。最常规选择。: IPv6网络通信。用于同一台Linux宿主机内的进程间通信(IPC),数据不经过网卡驱动,绕过TCP/IP协议栈,延迟极低。type(套接字类型): 决
Adam算法结合了动量法(Momentum)和RMSProp的思想,能够自适应调整每个参数的学习率。通过动态调整每个参数的学习率,在非平稳目标(如深度神经网络的损失函数)中表现优异。

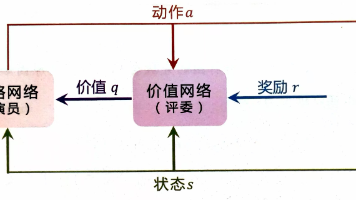
但是二者训练方法类似,都可以用n-step TD算法来更新网络参数。4. 用奖励执行TD算法更新Critic network的参数。Critic network和DQN完全不同。2. 根据现有策略做决策的随机采样,得决策。5. 将Critic network的输出。更新actor network的参数。上图来自王树森老师的《深度强化学习》