- @loyd3
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
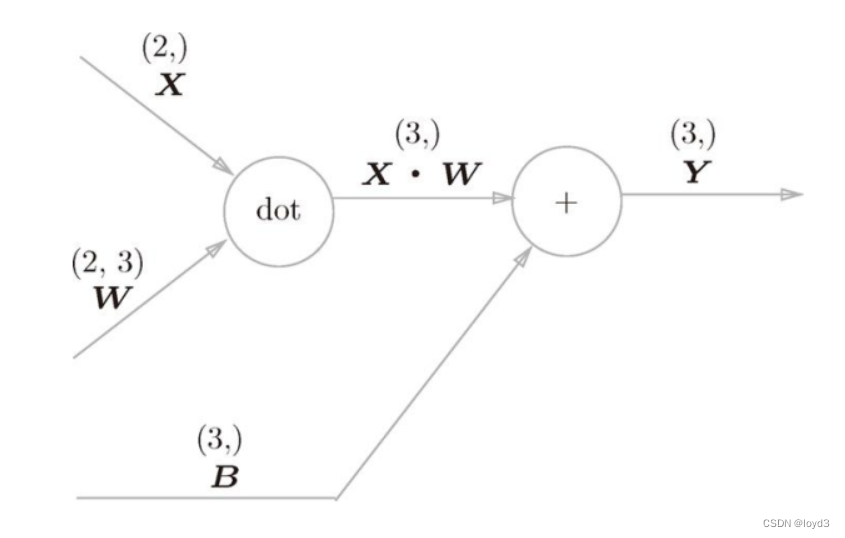
在上图的批处理版的数据流中,在各个数据的开头添加了批用的维度。之前的全连接神经网络的实现也对应了批处理,通过批处理,能够实现处理的高效化和学习时对 mini-batch 的对应。CNN 中,滤波器的参数就对应之前的权重。这里,假设输人大小为(H,W),滤波器大小为(FH,FW),输出大小(OH,OW),填充为P,步幅为S。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的
取值function get(key,sync = true) {try {if(sync){return uni.getStorageSync(key);}else{let data = '';uni.getStorage({key:key,success: function (res) {data = res.data;}});return data;}} catch (e) {
在某些移动设备尺寸下,两个相邻的div中间出现一条白线。可以通过给上半部分div的样式添加。上半部分div的样式。下半部分div的样式。
方法用于查找满足给定条件的数组中第一个元素的索引。它将回调函数作为参数,为数组中的每个元素执行该参数,直到满足条件为止。如果元素满足条件,回调函数应返回true,否则返回false。是一种有用的方法,用于查找满足给定条件的数组中元素的索引。它可以用于各种场景,例如根据特定属性对数组进行排序或查找特定元素的索引。方法中要比较的每个类型调用一次。然后使用两个索引之间的差异来确定类型数组的顺序。用于查找

以指定数量(10)各一组切分数组,组成一个数组,这个数组包含由最多指定数量(10)个数据的数组(数组集合)例如指定数量是10,原数组时[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]切分后组成新数组,[[1,2,3,4,5,6,7,8,9,10],[11,12,13,14,15]]slice() 方法从已有的数组中返回选定的元素。原数组不改变返回新选定的元素组成的新数组。
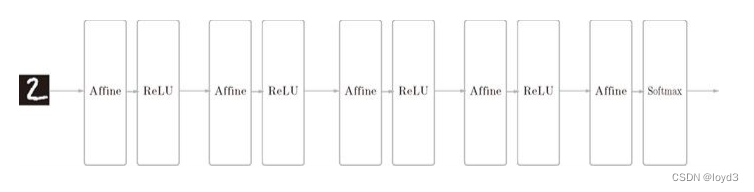
介绍下处理深度学习的框架DeZero,通过这个框架来了解自动微分是如何实现的指的是自动求出导数的做法(技术)。“自动求出导数”是指(而非人)求出导数。具体来说,它是指在对某个计算(函数)编码后计算机会自动求出该计算的导数的系统。自动微分。这是一种采用链式法则求导的方法。我们对某个函数编码后,可以通过自动微分高效地求出高精度的导数。反向传播也是自动微分的一种。反向传播相当于反向模式的自动微分。自动微
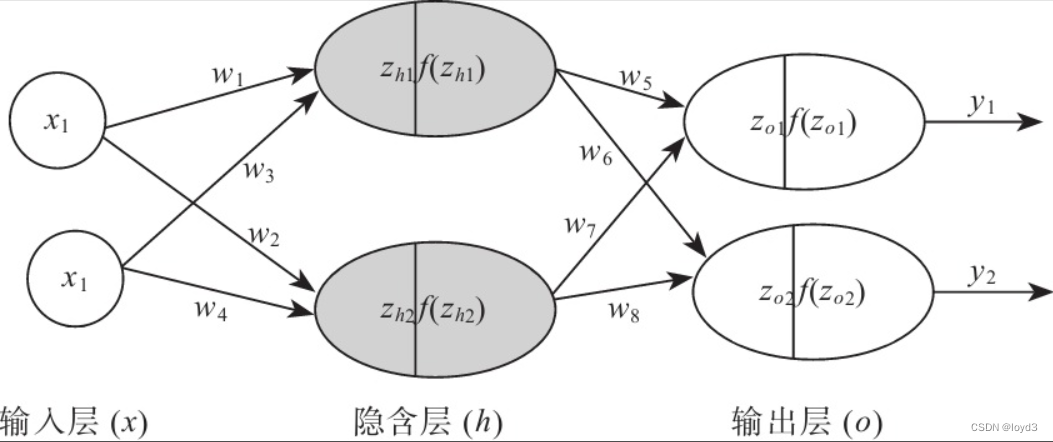
例如我们根据一个地区的若干年的PM2.5数值变化来估计某一天该地区的PM2.5值大小,预测值与当天实际数值大小越接近,回归分析算法的可信度越高。隐藏层的加权和(加权信号和偏置的总和)用a表示,被激活函数转换后的信号用z表示。此外,图中h()表示激活函数,这里我们使用的是sigmoid函数。如果使用矩阵的乘法运算,则可以将第1层的加权和表示成下面的式子。权重右下角按照“后一层的索引号、前一层的索引号
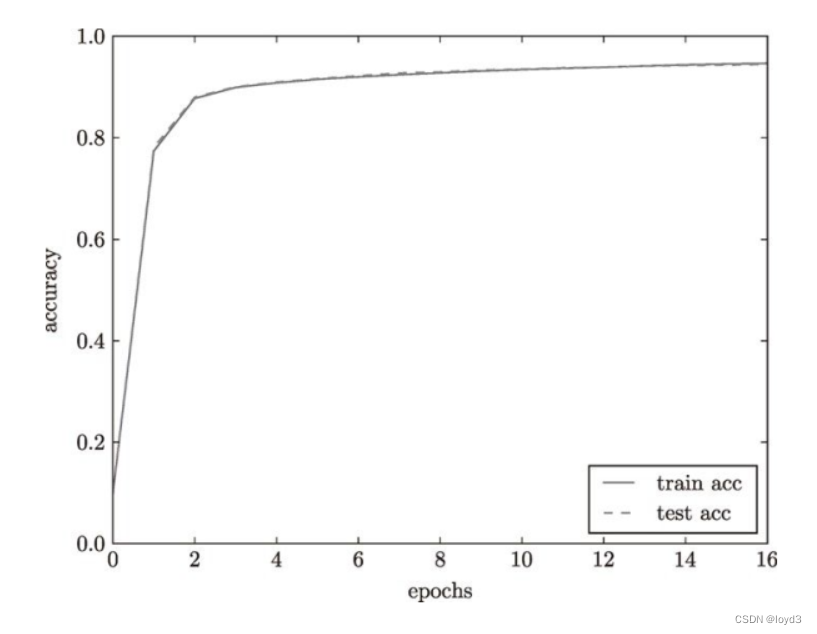
比如,对于10000笔训练数据,用大小为100笔数据的mini-batch进行学习时,重复随机梯度下降法100次有的训练数据就都被“看过”了。,因此,要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据。神经网络的学习的实现使用的是前面介绍过的mini-batch学习。深度学习的很多框架中,随机梯度下降法一般由一个名为。神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数据,即确
因此,神经网络的正向传播只需按照添加元素的顺序调用各层的forward()方法就可以完成处理,而反向传播只需要按相反的顺序调用各层即可。受到数值精度的限制,刚才的误差一般不会为0,但是如果实现正确的话,可以期待这个误差是一个接近0的很小的值。数值微分的计算很耗费时间,而且如果有误差反向传播法的话,就没有必要使用数值微分的实现了。之后,通过各个层内部实现的正向传播和反向传播,就可以正确计算进行识别处
如图所示,Softmax 层将输入 正规化,Cross Entropy Error 层接收 Softmax 的输出 和教师标签 ( t。这里要特别注意矩阵的形状,因为矩阵的乘积运算要求对应维度的元素数保持一致,通过确认一致性。)正是 Softmax层的输与监督标签的差,直截了当地表示了当前神经网络的输出与监督标签的。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性