




- @longxibo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 本书《DeepSeek 源码分析及企业应用实践》系统性地介绍了国产MoE大模型DeepSeek-V3/R1的技术架构、源码解析及企业级应用方案。全书分为六大部分: 基础架构:涵盖环境搭建、Transformer模块解析等入门内容 核心创新:深入分析MLA注意力、MoE专家系统、FP8量化等关键技术 开发实践:提供源码微调、推理引擎适配等二次开发指导 企业落地:详述私有化部署、合规设计、RAG

《Flowable 7.2源码解析与实战》是一本深入探讨开源工作流引擎的技术指南。全书从基础架构到高级特性,系统讲解了Flowable 7.2的核心机制、性能优化和生产实践。新版特性包括模块化重构、异步历史记录和增强的多租户支持。本书采用渐进式学习路径,涵盖流程部署、执行引擎、自定义扩展等关键内容,适合具备Java和数据库基础的开发者。通过源码调试和实战案例,读者将获得解决复杂业务问题和性能优化的

本文记录了在Ubuntu系统上基于Datasophon 1.2.1平台进行二次开发,验证实时数据入湖技术路线的过程。技术栈采用Kafka→Flink→Paimon→HDFS→ClickHouse的方案。重点包括:1)环境准备阶段补充Flink连接各组件所需的Jar包;2)创建Kafka Topic并生产测试数据;3)在ClickHouse中创建目标表;4)配置Flink连接YARN并启动SQL作业
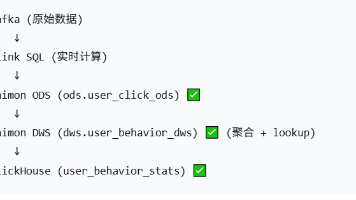
好,hadoop3.3.6集群部署,就写到这里。如需沟通:lita2lz。

摘要: 本文记录了在Ubuntu环境下基于DataSophon 1.2.1进行二次开发时,验证离线数据入湖(Paimon)的完整过程。重点解决了Spark 3.1.3与Paimon版本不兼容问题(升级至Spark 3.2.4)、HDFS权限配置、元数据存储切换为Hive Metastore等核心挑战。同时总结了12类典型问题及解决方案,包括Kafka依赖缺失、Derby权限错误、参数格式问题等,最
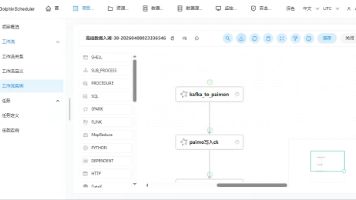
摘要: 本文记录了在Ubuntu环境下基于DataSophon 1.2.1进行二次开发时,验证离线数据入湖(Paimon)的完整过程。重点解决了Spark 3.1.3与Paimon版本不兼容问题(升级至Spark 3.2.4)、HDFS权限配置、元数据存储切换为Hive Metastore等核心挑战。同时总结了12类典型问题及解决方案,包括Kafka依赖缺失、Derby权限错误、参数格式问题等,最
本文记录了在Ubuntu系统上基于Datasophon 1.2.1平台进行二次开发,验证实时数据入湖技术路线的过程。技术栈采用Kafka→Flink→Paimon→HDFS→ClickHouse的方案。重点包括:1)环境准备阶段补充Flink连接各组件所需的Jar包;2)创建Kafka Topic并生产测试数据;3)在ClickHouse中创建目标表;4)配置Flink连接YARN并启动SQL作业
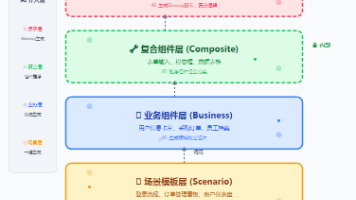
《零代码平台的AI架构实践:四层组件设计解决"最后一公里"难题》 本文探讨了零代码平台面临的"最后一公里"困境:用户能轻松拖拽界面,却在业务逻辑配置环节受阻。作者提出通过四层组件架构为AI赋能: 架构分层: 基础组件层(原子组件) 复合组件层(组合组件) 业务组件层(语义化组件) 模板层(完整页面) 关键设计: 严格的层级调用约束(禁止逆向/跨层调用) 组件
本文介绍了在麒麟V10系统上安装Datasophon 1.2.1时遇到的问题及优化方案。作者遇到麒麟系统权限限制和AKKA通讯不稳定的问题,特别是Agent分发时75%卡顿现象。通过分析源码发现问题出在AKKA通讯组件上,于是自主开发了兼容AKKA调用的简化版通讯框架Stable-Actor。优化后测试显示能稳定达到100%进度,但需要每次先删除集群并重启服务。作者表示这只是初步改进,后续可能还会
