




- @limingmin2020
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
PointNet、PointNet++、 F-PointNet一网打尽!

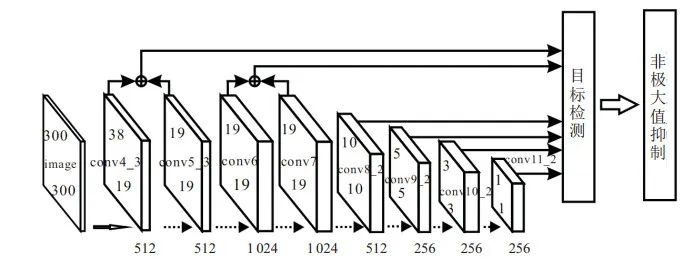
本文对现有的基础神经网络进行研究,结合VGGNet、SSD等技术,对背景部分进行处理,从而提高复杂背景下的目标检测精度。
使用卷积神经网络(CNN)架构的深度学习(DL)现在是解决图像分类任务的标准解决方法。但是将此用于处理3D数据时,问题变得更加复杂。首先,可以使用各种结构来表示3D数据,所述结构包括:1体素网格2点云3多视图4深度图对于多视图和深度图的情况,该问题被转换为在多个图像上使用2D CNN解决。通过简单定义3D卷积核,可以将2D CNN的扩展用于3D Voxel网格。但是,对于3D点云的情况,目前还不清
本文对目前最先进(SoTA)的道路成像系统和基于计算机视觉的路面坑洼检测算法进行了全面和深入的综述。
输入:一组点云(位于同一个平面,四边形物体的点云,如矩形或者正方形)输出:对应实际物体的长和宽输入的点云可能存在噪声干扰,需要通过一系列处理去除干扰,并在求到最小外接矩阵后进行优化,才可获得较准确的长和宽。主要进行如下几个步骤:1)将点云旋转到XOY平面;2)生成点云图像;3)进行膨胀腐蚀,填补空白区域;4)进行连通域标记,取最大连通域;5)获取图像的边缘;6.求边缘部分的最小外接矩阵并进行优化。
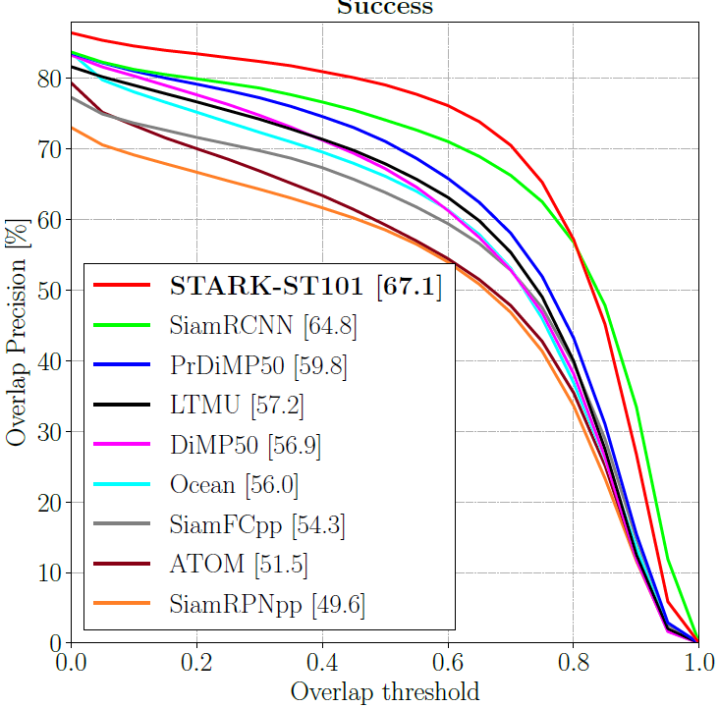
本文简短介绍大连理工大学和微软亚洲研究院合作的最新工作:Learning Spatio-Temporal Transformer for Visual Tracking,代码已开源。
PointNet、PointNet++、 F-PointNet一网打尽!
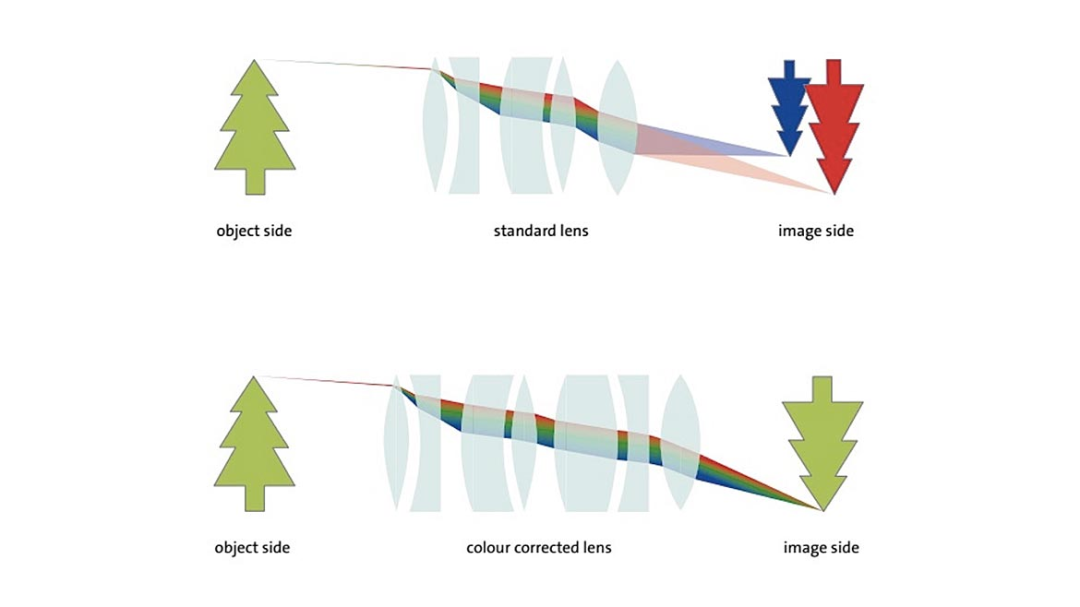
不同波长的光在使用同一个镜头的时候会产生不同的效果,而不同波长的波段范围成像主要应用也不太一样,这在实际项目应用中具有重要参考意义。
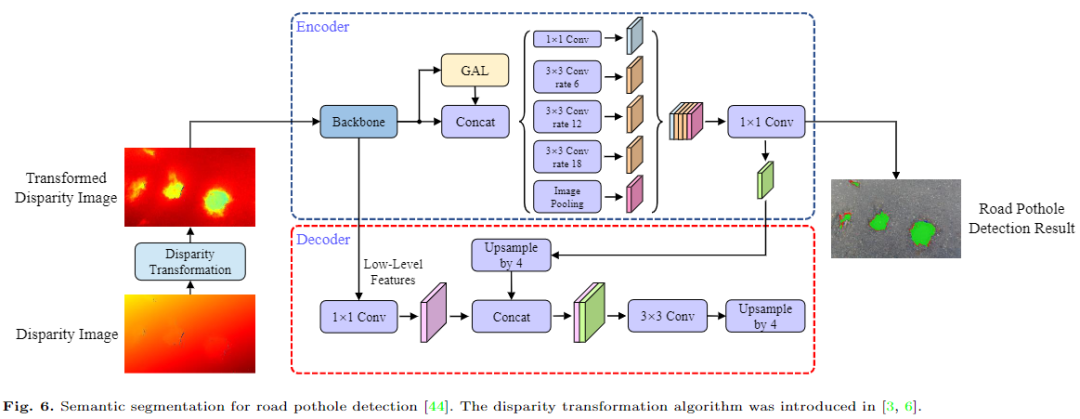
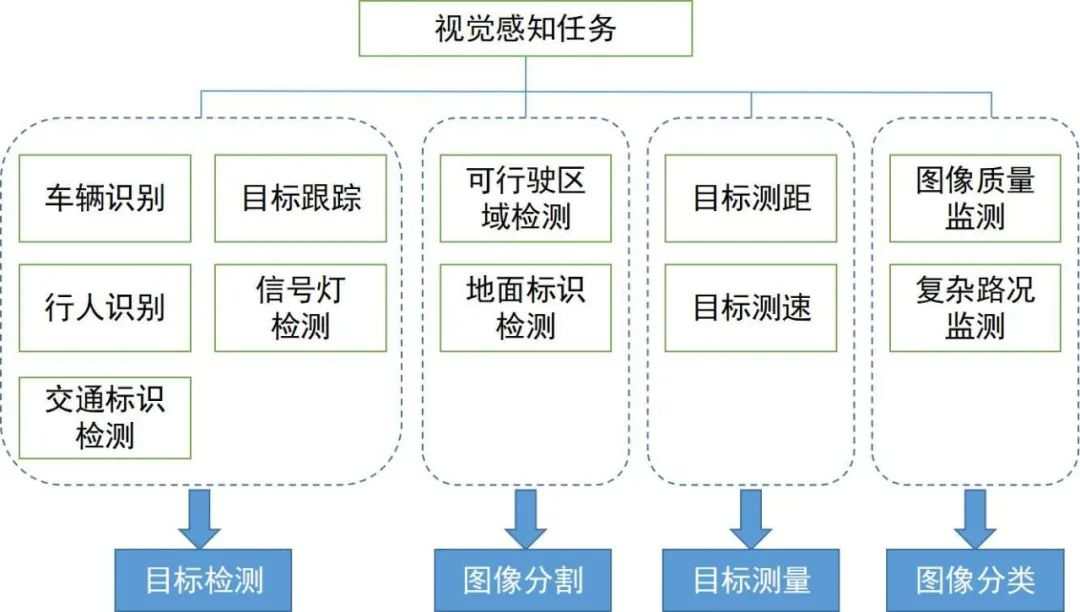
本节我们先从广泛应用于自动驾驶的几个任务出发介绍2D视觉感知算法,包括基于图像或视频的2D目标检测和跟踪,以及2D场景的语义分割。
本文总结了产生深度暗示(即立体感)的几种情况。产生深度暗示主要有两种:心理深度暗示和生理深度暗示。心理深度暗示主要由平时的经验积累获得。即使用单眼观看也会使人有3D效果。它主要包括以下几种:视网膜像的大小。我们通过后天学习已经确知一个物体大小时,可以通过判断看见该物体的大小来粗略估计它的远近。线性透视。景物随着距离的增加而线性减小,可以估计它的远近。例如,道路两旁的灯和房屋越远越小。如图所示 :被