- @l12345sy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
线性回归模型评估中,MAE、MSE和RMSE是三种常用的指标,它们各自从不同的角度衡量预测值与真实值之间的差距。
极端梯度提升树,与传统的梯度提升决策树(GBDT)相比,XGBoost通过引入来控制模型的。
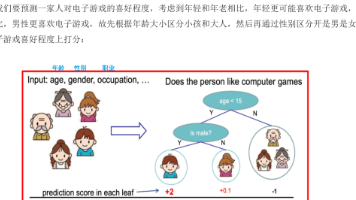
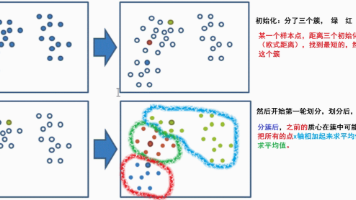
本文介绍了聚类算法的基本概念和实现方法,重点讲解了K-Means聚类算法及其评估指标。聚类算法属于无监督学习,通过样本相似性进行分类,常见方法包括K-means、层次聚类等。K-Means算法通过迭代优化质心位置实现聚类,适用于数据探索初期。文章详细演示了使用sklearn实现K-Means的完整流程,并介绍了三种评估指标:SSE(误差平方和)结合肘部法确定最佳K值;轮廓系数法(SC)衡量内聚度和
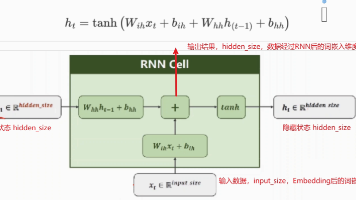
循环神经网络(RNN)是一种处理序列数据的深度学习模型,具有记忆功能,能存储并利用历史信息。RNN可分为不同类型(如NvsN、LSTM、GRU等),其核心结构通过隐藏状态h传递序列信息。API使用中需注意输入/输出维度匹配,默认全零初始化h0。RNN优点包括结构简单、资源要求低,在短序列任务中表现良好;但存在梯度消失、训练爆炸风险,且不适用于长序列任务。深层理解表明批量处理与单个样本处理结果等效。
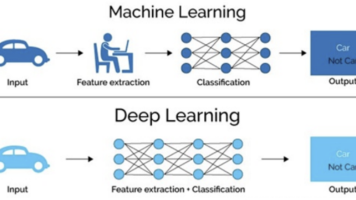
AI、ML和DL是递进关系:AI是目标,ML是实现方式,DL是ML的一种特殊方法。深度学习通过深层神经网络自动提取特征,擅长处理文本、图像等非结构化数据。与传统机器学习相比,DL需要更多数据和算力,但能实现更高精度,缺点是"黑箱"特性明显。主流框架包括PyTorch(研究首选)、TensorFlow(工业部署)以及国产的PaddlePaddle和MindSpore。DL在大数据
矩阵乘法运算要求第一个矩阵 shape: (n, m),第二个矩阵 shape: (m, p), 两个矩阵点积运算 shape 为: (n, p)。点乘指(Hadamard)的是。
倒排索引是一种将关键词映射到文档列表的数据结构,用于快速检索。在向量搜索中,IVF_FLAT算法将这一概念应用于聚类中心:先通过K-Means聚类建立向量到聚类中心的倒排索引,搜索时先找到最近的nprobe个聚类中心,再对其中的向量进行精确距离计算。这种方法结合了倒排索引的快速筛选(IVF)和原始向量的精确比对(FLAT),显著提升了大规模向量搜索的效率,避免了暴力扫描的计算开销。
AI、ML和DL是递进关系:AI是目标,ML是实现方式,DL是ML的一种特殊方法。深度学习通过深层神经网络自动提取特征,擅长处理文本、图像等非结构化数据。与传统机器学习相比,DL需要更多数据和算力,但能实现更高精度,缺点是"黑箱"特性明显。主流框架包括PyTorch(研究首选)、TensorFlow(工业部署)以及国产的PaddlePaddle和MindSpore。DL在大数据
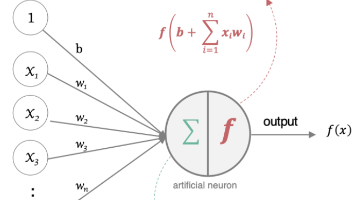
人工神经网络(ANN)是模仿生物神经网络的数学模型,由输入层、隐藏层和输出层组成。输入层接收原始数据,隐藏层通过加权求和和激活函数进行特征学习,输出层产生最终结果。神经网络通过初始化参数和激活函数(如ReLU、Sigmoid等)实现特征提取和模式识别,适用于分类、回归等任务。参数初始化方法包括Kaiming、Xavier等,激活函数选择取决于网络层和任务类型。