




- @heaven522
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
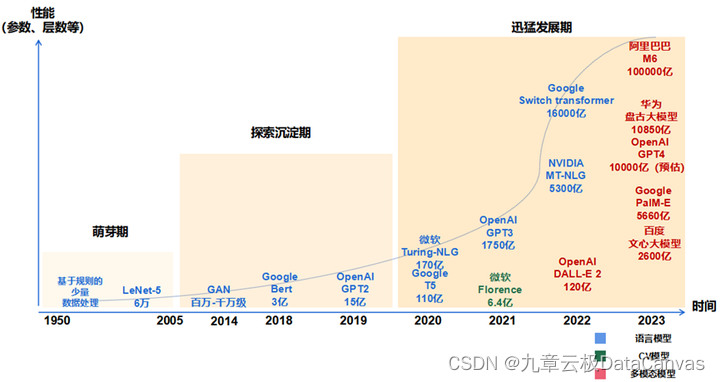
因为所有的预测工作,都是基于对上下文的表示来完成的,可以想象由于每个词的向量,和整个匹配的预测过程,都是基于神经网络可学习的参数来完成,所以我们就可以利用大规模的数据来自动地学习这些词向量,自动地去更新神经网络的权重(嵌入矩阵)。即我们可以利用词的上下文词来知道这个词的意思,或来表示这个词。该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表

随着科技的飞速发展,人工智能已经逐渐渗透到各行各业,为许多领域带来了翻天覆地的变化。。华为作为全球领先的科技企业,一直致力于将人工智能技术应用于医药领域,推动传统医学与现代科技的深度融合。其中,华为中医药大模型便是其在这一领域的重要成果之一。。这一天,浙江九为健康科技股份有限公司与华为云计算技术有限公司在华为深圳总部签署了中医药大模型全面深化合作协议,共同推出了这一创新性的中医药大模型。该模型的出

随着科技的飞速发展,人工智能已经逐渐渗透到各行各业,为许多领域带来了翻天覆地的变化。。华为作为全球领先的科技企业,一直致力于将人工智能技术应用于医药领域,推动传统医学与现代科技的深度融合。其中,华为中医药大模型便是其在这一领域的重要成果之一。。这一天,浙江九为健康科技股份有限公司与华为云计算技术有限公司在华为深圳总部签署了中医药大模型全面深化合作协议,共同推出了这一创新性的中医药大模型。该模型的出
视觉语言预训练提高了许多下游视觉语言任务的性能,例如:图文检索、基于图片的问答或推理。有朋友要问了,除了在公开的学术任务上使用更大的模型/更多的数据/技巧把指标刷得很高,

大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
语言建模的研究始于20世纪90年代,最初采用了统计学习方法,通过前面的词汇来预测下一个词汇。然而,这种方法在理解复杂语言规则方面存在一定局限性。随后,研究人员不断尝试改进,其中在2003年,深度学习先驱Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,使用了更强大的神经网络模型,这相当于为计算机提供了更
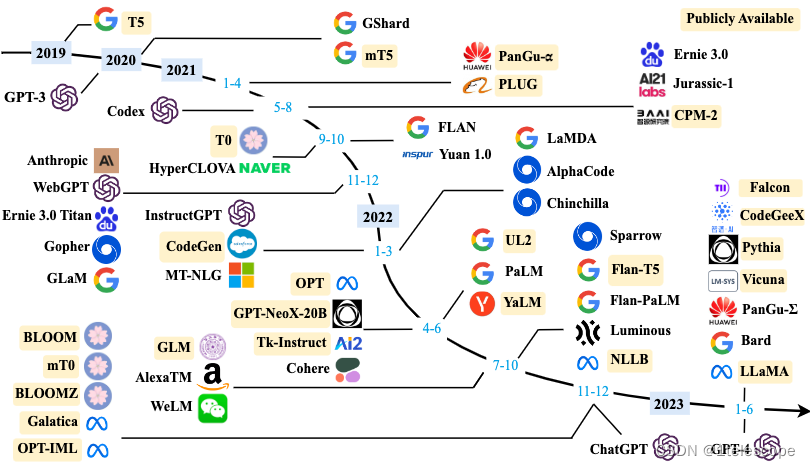
自2018年BERT发布以来,“预训练+微调”成为语言模型的通用范式。以ChatGPT为代表的大语言模型针对不同任务构造Prompt来训练,本质上仍然是预训练与微调的使用范式。千亿规模的参数微调需要大量算力,即使提供了预训练的基座模型,一般的研究机构也很难对其进行全量微调(即对所有参数进行微调)。为了应对这个问题,相关学者提出了PEFT(Parameter-Efficient Fine-Tunin

与其在AI抢占就业机会的危机中患得患失,不如快点接受这个新技术,将AI引入自己的工作中,通过AI来提升自己的生产力和创造力。AI大模型通过学习大量的图像数据和构建更深更复杂的神经网络,使计算机能够对图像进行更加准确的识别和分析。总的来说,“大模型”应该是基于具有超级大规模的、甚至可以称之为“超参数”的模型,需要大量的计算资源、更强的计算能力以及更优秀的算法优化方法进行训练和优化。大数据时代,越来越

大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。