




- @he_wen_jie
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
• 分布改变的补偿:当对多数类进行降采样时,训练集中多数类的概率分布就被人为地改变了。如果直接在这个分布上训练,模型会低估多数类的真实重要性。这时,给降采样后的样本赋予权重(例如,降采样10倍,则权重设为10),正是在补偿这种分布差异。这个权重可以被理解为重要性权重wxpxqxwxpxqx的一种实践,其中pxp(x)px是真实分布,qxq(x)qx是降采样后的分布。
• 建议分布pxp(x)px: 当前训练中的 LLM 策略(Policy)。我们利用该模型针对同一个 Prompt 生成NNN个不同的候选响应。• 评估指标: 奖励模型(Reward Model, RM)。它作为一个判别器,为这NNN个样本分别打分rxyr(x,y)rxy,分值高低代表了样本符合人类价值观或逻辑要求的程度。• 目标分布1x1(x)1x: 这是一个理想的“对齐分布”,即那些奖励得分极
数字 M的四位表示 UUID 版本,当前规范有5个版本,M可选值为1, 2, 3, 4, 5。这5个版本使用不同算法,利用不同的信息来产生UUID,各版本有各自优势,适用于不同情景。UUID是一个 128 位无符号整数,通常使用十六进制字符串来表示,以连字号分隔的五组来显示,形式为 8-4-4-4-12,总共有 36个字符(即三十二个英数字母和四个连字号)。数字 N的一至四个最高有效位表示 UUI
首先安装一个uv,用来管理虚拟环境。
sorted排序val=[3,5,1,4,2]# 递增res = sorted(val)print res# output [1,2,3,4,5]# 递减res = sroted(val,reverse=True)print res# output [5,4,3,2,1]按某个关键字排序val = [(5,5),(6,1),(6,2),(3,3),(2,2),(2,1)...
• 建议分布pxp(x)px: 当前训练中的 LLM 策略(Policy)。我们利用该模型针对同一个 Prompt 生成NNN个不同的候选响应。• 评估指标: 奖励模型(Reward Model, RM)。它作为一个判别器,为这NNN个样本分别打分rxyr(x,y)rxy,分值高低代表了样本符合人类价值观或逻辑要求的程度。• 目标分布1x1(x)1x: 这是一个理想的“对齐分布”,即那些奖励得分极
1.困惑之源半年前第一次做推荐算法,无意中碰到了一个问题,我使用LR模型对用户和商品进行联合打分,其中使用了所谓的交叉特征,这个问题思考了大半年终于有了一些思路。问题是这样的,我统计了不同用户在不同类目上的点击率,以此作为所谓的交叉特征,并且将点击率做了一个线上表,当用户请求时,直接查询用户历史所有的类目偏好。其中ucucuc表示用户(user)和类目(cate)的交叉特征,这里为点击率,下标表示
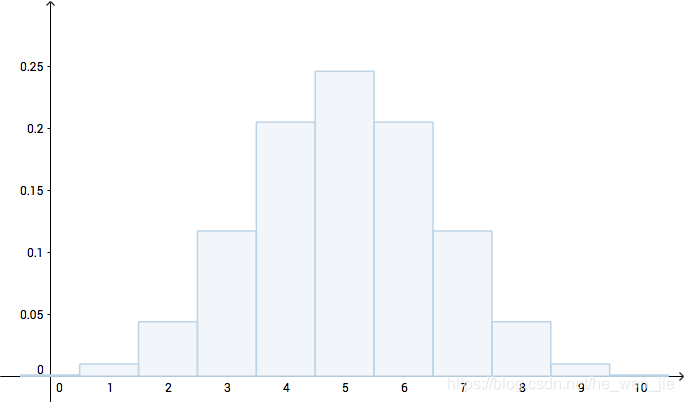
假设检验假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断。样本间差异有两种方式导致这两个或几个样本均数(或率)来自同一总体,其差别仅仅由于抽样误差即偶然性所造成。这两个或几个样本均数(或率)来自不同的总体,即其差别不仅由抽样误差造成,而主要是...
glibc(GNU C Library)的头文件与C++标准库头文件在Linux系统中的路径存在显著差异,主要源于其功能定位和编译器管理方式的不同。**3. 内核相关路径(开发板/嵌入式)**。- sys/mman.h:内存管理(如mmap)- sys/socket.h:套接字接口。- sys/time.h:时间操作函数。
MovieLens 数据集是由明尼苏达大学的GroupLens研究小组维护的一个广泛使用的电影评分数据集,主要用于推荐系统的研究。该数据集包含用户对电影的评分、标签以及其他相关信息,是电影推荐系统开发与研究的常用数据源。
