




- @gangyikeji
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
淘系技术部隶属于阿里巴巴新零售技术事业群,支撑淘宝、天猫核心电商以及闲鱼、躺平等创新业务,服务9亿用户,赋能各行业1000万商家。淘系技术打造了全球领先的线上新零售技术平台,并作为核心技术团队保障了11次双十一购物狂欢节的成功。通过不断探索和衍生颠覆型互联网新技术,打造了业内领先的淘宝直播、智能营销等技术体系,并且通过技术驱动商业,在家装家居赛道中成功开创了躺平新业务,以更加智能、友好、普惠的科技
对于数据挖掘项目,本文将学习应该从哪些角度做特征工程?从哪些角度做数据清洗,如何对特征进行增删,如何使用PCA降维技术等。

简介教程介绍如何在轻量应用服务器上,以WordPress为镜像的网站搭建及管理。背景知识轻量应用服务器轻量应用服务器是面向单机应用场景的新一代计算服务,提供应用一键部署、一站式域名解析、网站发布、安全、运维、应用管理等服务。主要应用场景有:搭建小型网站;建立个人博客;建立论坛社区;构建知识效率管理工具;建立个人学习环境;搭建小型电商网站;快速搭建开发环境。WordPressWordPress是使用
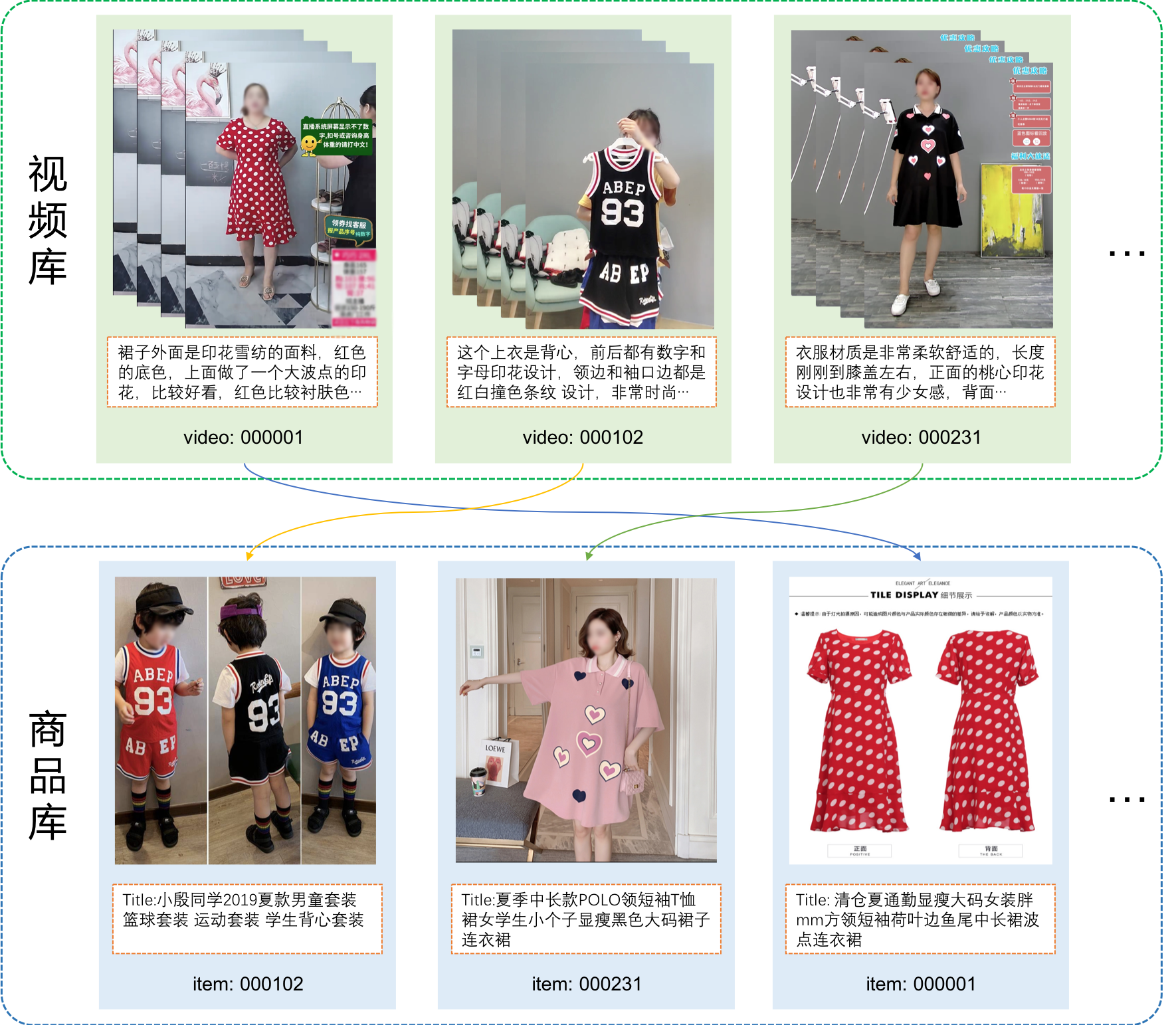
CBLUE的全称是Chinese Biomedical Language Understanding Evaluation Benchmark,包括医学文本信息抽取、医学术语标准化、医学文本分类和医学问答4大类常见的医学自然语言处理任务。CBLUE为研究者们提供真实场景数据的同时,也为多个任务提供了统一的测评方式,目的是促进研究者们关注AI模型的泛化能力。

查看本文全部内容,欢迎访问天池技术圈官方地址:第二届阿里巴巴大数据智能云上编程大赛亚军比赛攻略_北方的郎队_天池技术圈-阿里云天池

介绍如何在半小时内,通过阿里云容器ACK服务和容器网络文件系统CNFS服务搭建一个简单的弹性、高可用NGINX网站。,11 月 9 日至 11 月 23 日期间,完成部署即可获得“TOMY 多美卡合金车模一辆”。地址:https://developer.aliyun.com/adc/series/activity/1111体验目标本文介绍如何在半小时内,通过阿里云容器ACK服务和容器网络文件系统C
通过本次比赛,认识了各个学校的大佬,他们的方法也让我们队有一种“恍然大悟”的感觉。例如我们在比赛中虽然想到了通过添加分隔符的方式来攻击模型,但是在文本的每个字符之间添加分隔符会显著增加词汇层面的杰卡德距离,而如果在样本末尾添加扰动字符就不会出现这些问题。再如,很多组的同学都提到替换“你”这个字对模型影响特别大(我们直接把这个字用停用词表过滤掉了),以及对新词替换次数的阈值应当有限制等问题,这些问题

人工智能是国家战略性新兴产业,制造业是国民经济的主体,随着人口红利的消失,加强设备自动化改造,提高生产自动化程度,减小劳动强度,改善作业环境,已经成为制造业的普遍共识。天池大赛开放出一批在实际生产过程中积累的数据集,涵盖纺织、食品饮料、非金属制品等行业,希望通过计算机视觉以及人工智能等技术手段来帮助制造业提高质检效率以及效果、降低质检成本。

本场景将提供一台基础环境为CentOS的ECS(云服务器)实例和已经创建好的PolarDB数据库实例。我们将会在这台服务器上安装WordPress,帮助您快速搭建自己的云上博客。
简介教程介绍如何在轻量应用服务器上,以WordPress为镜像的网站搭建及管理。背景知识轻量应用服务器轻量应用服务器是面向单机应用场景的新一代计算服务,提供应用一键部署、一站式域名解析、网站发布、安全、运维、应用管理等服务。主要应用场景有:搭建小型网站;建立个人博客;建立论坛社区;构建知识效率管理工具;建立个人学习环境;搭建小型电商网站;快速搭建开发环境。WordPressWordPress是使用