- @eyexin2018
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些向量在一个连续的向量空间中,保持了原始数据的语义或结构信息,使得相似的数据点在空间上距离较近。OLLAMA_KEEP_ALIVE=24h设置模型加载到内存中保持24个小时(默认情况下,模型在卸载之前会在内存中保留 5 分钟)果然获取维度失败是有原因的,有些模型是支持嵌入的,有些则不支持,如qwen-1.5B, deepseek-70B它就支持,查看API文档。支持嵌入的一般是比较小的模型,灵活
感觉没什么好的学习材料和网站,网上资料本就很少,有代码的更少,而且呢,这些代码还基本上都是TensorFlow1.x版本的,和2.x不兼容,需要修改。我想了想既然我一直在debug,那不如把这一篇文章写成一个debug集锦,也方便以后解决问题。'variables’替换tf.GraphKeys.GLOBAL_VARIABLES。问题成环了,这就是死循环啊。回到了error No1。
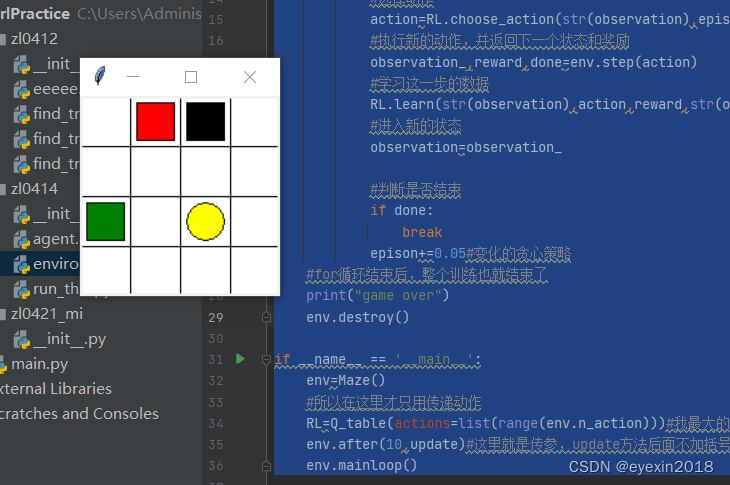
注意:这里的update和main函数知识对该环境的一个简单测试,不是智能体的行动,在使用强化学习训练的过程中,它们并不执行。环境类总结起来就是定义了初始化的参数,构建迷宫,重置函数(每一次游戏结束后需重置到起始的环境),每一步怎么走的。调用前面写好的两个类,并写好更新的过程即可运行,这里可以设定训练的次数,贪婪策略所用的系数以及其动态变化的控制。智能体的部分比较通用和固定,总结起来就是:参数的初
设置 do_sample: false,取消随机抽样策略。
MLlib采用Scala语言编写,借助了函数式编程设计思想,开发人员在开发的过程中只需要关注数据,而不需要关注算法本身,因为算法都已经集成在里面了,所以只需要传递参数和调试参数。MLlib主要包含两部分,分别是底层基础和算法库。其中底层基础包括spark的运行库、矩阵库、和向量库,向量接口和矩阵接口是基于Netlib和BLAS/LAPACK开发的线性代数库Breeze;算法库包括分类、回归、聚类、
安装run包驱动时,会将动态库libdcmi.so和头文件dcmi_interface_api.h拷贝到“/usr/local/dcmi/”目录下。终于搞明白华为的这一套架构了,ascend-toolkit的latest是用于存放最近安装的版本,并非是最高的版本,所以存在多个也无所谓。失败了,检查发现是CANN版本不一致导致,toolkit的版本是8.3,驱动的版本是8.0.0。执行如下命令,完成
backend and will fall back to run on the CPU. This may have performance implications. (function npu_cpu_fallback)Exception in thread Thread-5:原模型直接推理可以跑起来,但是回答问题的时候它没法用npu,还要迁移到CPU计算,这个过程可能需要花费数小时,官方解
尝试关闭expandable_segments不行,export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:32,garbage_collection_threshold:0.6,expandable_segments:True。找到原因了,从这里开始-CANN社区版8.0.0.alpha001开发文档-昇腾社区。找到原因了,内存池扩展段功能是高级特性需要H
bf16是Facebook新提出的深度学习数据格式,华为的机器并不一定支持,所以将其设置为false。这个问题在最新的A2系列服务器可直接解决,驱动用24及以上。只有A2系列的才支持。确实是的,在ascend-toolkit下ls。重新装kernel算子,opp_kernel。