




- @duzm200542901104
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在实际任务中,原始数据集未必完全含有解决任务所需要的充足信息。通过分析任务场景的复杂性和当前数据集的短板,对现有数据有针对性做一些数据增强/增广的策略的修改,以提供更加多样性的、匹配任务场景复杂性的新数据,往往可以显著的提高模型效果。数据增强是一种挖机数据集潜力的方法,可以让数据集蕴含更多让模型有效学习的信息。这些方法是领域和任务特定的,扩大训练数据集,抑制过拟合,提升模型的泛化能力。
1、定义:监督学习是从标记的训练数据来推断一个功能的机器学习任务。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。2、举例:通过已知病例学习诊断技术那样,计算机要通过学习才能具有识别各种事物和现象的能力。3、使用场景:监督学习方法是目前研究较为广泛的一种机器学习方法,例如神经网络传播算法、决策树学习算法。
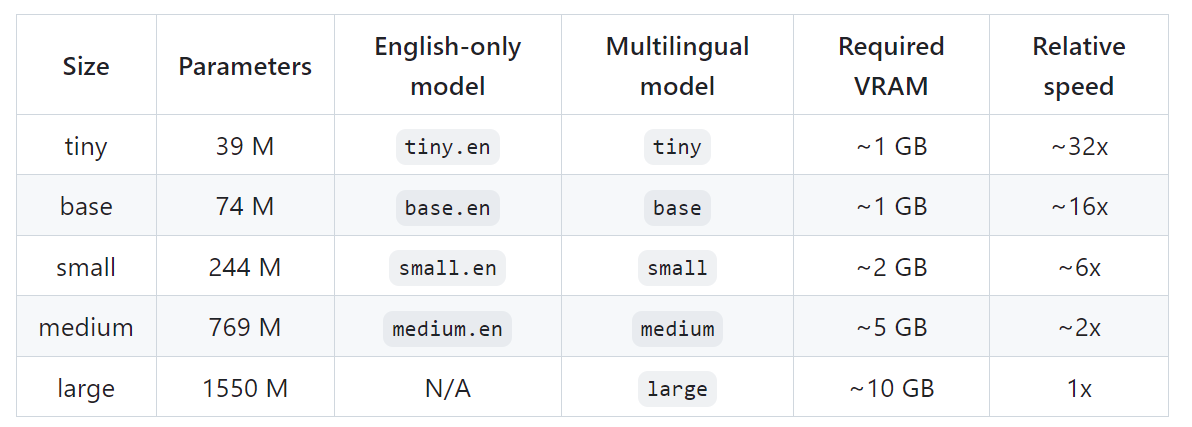
它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。如果为true,则前一个模型的输出会作为下一个窗口的提示,禁用可能导致窗口之间的文本不一致,但该模型不太容易陷入故障循环。在CPU接口下,torch使用的线程数量,取代 MKL_NUM_THREADS/OMP_NUM_THREADS。在srt和vtt中说出的每个单词下面加下划线(条件:--word_
在前面的几篇中,我们学习了使用卷积神经网络进行图像分类,比如手写数字识别是用来识别0~9这十个数字。与图像分类处理单个物体的识别不同,目标检测它识别的不仅是物体,还是多个物体,不仅要确定物体的分类,还要确定物体的位置。比如下图:目标检测不仅要告诉我们这张图片上既有小狗也有小猫,还要告诉小狗处于左边红色方框内,而小猫处于右边的红色方框内。也即目标检测的输出结果是【目标分类+目标坐标】
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,直接翻译过来就是大模型的低秩适配2021年微软提出的LoRA,它的灵感来自于 Li和 Aghajanyan等人的一些关于内在维度(intrinsic dimension)的发现:模型是过参数化的,它们有更小的内在维度(low intrinsic dimension)。于是假设模型在任务适配过程中权

当模型参数越来越大的情况下,如果我们的GPU内存比较小,那么就没办法直接进行全参数微调,此时我们可以借助deepspeed来进行微调。1、deepspeed的配置文件:deepspeed.json。当前我们利用44G的GPU全参微调了Qwen2.5-3B的模型。这里我们启动的ZeRO-1:优化器状态跨 GPU 分区。

本文介绍了RAG技术中语义检索的两种向量表示方法:稀疏向量(基于字词匹配)和稠密向量(基于语义)。通过BGEM3FlagModel库演示了如何生成这两种向量,并提供了处理向量格式的注意事项:稀疏向量需转换为{Long,Float}键值对,稠密向量需从np数组转为普通数组才能JSON化。代码示例展示了如何正确提取和处理这两种向量,为语义检索提供基础数据支持。
利用multiprocessing的Process可以非常方便的实现多进程架构,另外使用它的Queue也可以非常便捷的进行进程间通信,这样每个进程指定特定的GPU卡,就实现了GPU卡的利用。
member:PRIMARY> rs.status(){ "ok" : 0, "errmsg" : "not authorized on admin to execute command { replSetGetStatus: 1.0 }", "code" : 1
在前面的几篇中,我们学习了使用卷积神经网络进行图像分类,比如手写数字识别是用来识别0~9这十个数字。与图像分类处理单个物体的识别不同,目标检测它识别的不仅是物体,还是多个物体,不仅要确定物体的分类,还要确定物体的位置。比如下图:目标检测不仅要告诉我们这张图片上既有小狗也有小猫,还要告诉小狗处于左边红色方框内,而小猫处于右边的红色方框内。也即目标检测的输出结果是【目标分类+目标坐标】