




- @a99615
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本项目构建了一个电商知识图谱系统,采用Neo4j图数据库存储数据,结合MySQL关系型数据库和多种技术栈实现。系统包含数据准备、实体抽取模型训练、知识图谱构建和智能问答四个核心模块。通过Label-studio进行数据标注,训练BERT模型实现实体抽取;利用Python连接MySQL和Neo4j完成数据同步;最后基于LangChain框架开发问答系统,支持语义检索和自然语言回答。项目实现了商品分类
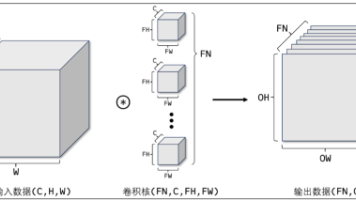
卷积神经网络(Convolutional Neural Network,CNN)常被用于图像识别、语音识别等各种场合。它在计算机视觉领域表现尤为出色,广泛应用于图像分类、目标检测、图像分割等任务。
LLM微调之实战,SFTTrainer官方案例、LoRA/QloRA微调案例、Unsloth、分布式训练、LLaMA Factory
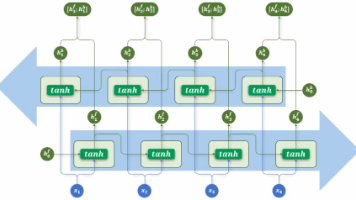
RNN(Recurrent Neural Network)循环神经网络,LSTM
LangChain是2022年10月,由哈佛大学的Harrison Chase(哈里森·蔡斯)发起研发的一个开源框架,用于开发由大语言模型(LLMs)驱动的应用程序。比如,搭建Agent、问答系统(QA)、对话机器人、文档搜索系统等。LangChain是一个帮助你构建LLM应用的全套工具集。这里涉及到prompt构建、LLM接入、记忆管理、工具调用、RAG、Agent开发等模块。LangChain
LangChain是2022年10月,由哈佛大学的Harrison Chase(哈里森·蔡斯)发起研发的一个开源框架,用于开发由大语言模型(LLMs)驱动的应用程序。比如,搭建Agent、问答系统(QA)、对话机器人、文档搜索系统等。LangChain是一个帮助你构建LLM应用的全套工具集。这里涉及到prompt构建、LLM接入、记忆管理、工具调用、RAG、Agent开发等模块。LangChain
HuggingFace是一个开源的AI生态系统,通过Transformers库降低了BERT、GPT等预训练模型的使用门槛。其核心功能包括:1)模型加载(AutoModel类自动适配任务头);2)Tokenizer处理文本到张量转换;3)Datasets库简化数据处理;4)支持NLP、CV等多模态任务。文中还展示了基于BERT的中文情感分析实战案例,涵盖数据预处理、模型训练(使用BCEWithLo

早期的自然语言处理需为每个任务单独训练模型,严重依赖人工标注数据,存在两大局限:语言知识难以复用导致训练成本高;专业领域标注数据获取困难。为此研究者提出"预训练+微调"范式:先在大规模未标注语料上学习通用语言规律,再通过少量标注数据适配具体任务。
此前的Seq2Seq模型通过Attention机制取得了一定提升,但由于整体结构仍依赖RNN,依然存在计算效率低、难以建模长距离依赖等结构性限制。Transformer完全摒弃了RNN结构,转而使用注意力机制直接建模序列中各位置之间的关系。与基于RNN的Seq2Seq模型一样,Transformer的解码器采用自回归方式生成目标序列。不同之处在于,每一步的输入是此前已生成的全部词,模型会输出一个与
