




- @Xyz_Overlord
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
创建张量、转换、张量索引、形状、升降维、交换维度、拼接

数据结构:是储存和组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。算法:用来实现业务目标的方法和思路。二者的关系:数据结构 + 算法 = 程序,算法是为了解决实际问题而设计的,数据结构是算法需要处理问题的载体。

有特征有标签(结果驱动),出现两大问题是:分类任务(标签是离散的,函数输出有限个离散值)和回归任务(标签是连续的,函数输出连续的值)有特征无标签(数据驱动),出现问题:聚类任务,降维任务,异常检测任务…2.基于模型的学习:通过编写机器学习算法,让加器自己学习从数据中获得的规律(模型),然后进行预测。数据集划分:训练集(训练模型)和测试集(测试模型),一般对应占比8:2或者7:3。奥卡姆剃刀原则:给

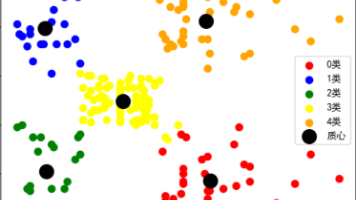
根据样本之间的相似性,将样本划分到不同的类别中的一种无监督学习算法。细节:根据样本之间的相似性,将样本划分到不同的类别中;不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。聚类算法的目的是在没有先验知识的情况下,自动发现数据集中的内在结构和模式。计算样本和样本之间的相似性,一般使用欧式距离。
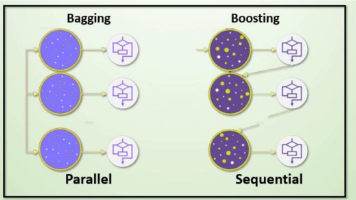
集成学习:(Ensemble Learning)是一种机器学习范式,它通过构建并结合多个模型来完成学习任务,获得更好的泛化性能。核心思想:通过组合多个弱学习器来构建一个强学习器。bagging思想:有放回的抽样;平权投票,多数表决方式决定预测结果;并行训练。boosting思想:全部样本(重点关注上一训练器不足的地方训练);加权投票的方式;串行训练。
BERT(Bidirectional Encoder Representations from Transformers)是由Google研究团队在2018年提出的一种基于Transformer架构的预训练语言模型,其全称为"来自Transformer的双向编码器表示"。这一革命性模型的问世,标志着自然语言处理(NLP)领域进入了一个全新的时代,极大地推动了语言理解技术的发展。在BERT出现之前,

(英文:Large Language Model,缩写LLM)大型语言模型是一种基于深度学习的人工智能系统,通过分析海量文本数据学习语言模式、世界知识和推理能力。这些模型通常包含数十亿甚至数千亿个参数,能够生成类似人类的文本、回答问题、翻译语言以及执行各种与语言相关的任务。
