




- @XLionXxxx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
该模型旨在解决化学图像理解与文本分析之间的不兼容问题,通过结合视觉 Transformer (ViT)、多层感知机 (MLP) 和大型语言模型 (LLM) 的优势,实现了对化学图像和文本的全面推理。可以看到模型针对图像准确描述了图像的内容是黄色的液氮罐,接着我们可以继续问它一个问题,比如我们输入「液氮的化学分子式是什么」。平台会自动选择合适的算力资源和镜像版本,这里使用的是英伟达 A100的算力和

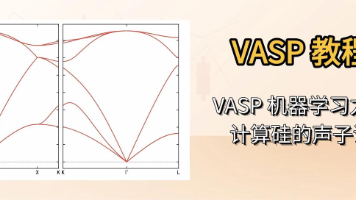
是一个计算机程序,用于从第一性原理进行原子尺度材料建模,例如电子结构计算和量子力学分子动力学。Phonopy()是一款用于在简谐和准简谐水平下计算声子能带结构、热学性质、群速度以及其他与声子相关物理量的 python 工具包。本次教程我们将使用自动化脚本来进行机器学习力场演示计算流程。
现在的 AI 画图工具,像极了手艺精湛却耳背的 Tony 老师——你说招牌写开业大吉,他画出一串连考古学家都破译不了的符号。开源,为了好用而不只是能用,由智谱华章以开源形式发布的 GLM-Image 打破「高性能=闭源收费」的潜规则。毕竟,我们要的不是抽卡式的运气游戏,而是能听懂复杂需求的靠谱搭档。页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。

摘要:Google DeepMind 推出的 Gemma-4-31B-it 模型在技术资料整理中展现出显著优势,其基于Gemini3 技术体系,强化了长上下文建模与推理能力。该模型支持 256K 上下文和图文输入,能一次性完成原本需要人工逐步推进的复杂任务,大幅提升工作效率。

运行「python3 -m vllm.entrypoints.openai.api_server --model /input0/Qwen-1_8B-Chat/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-

NVIDIA 最新推出的 LocateAnything-3B 模型通过创新的 ParallelBoxDecoding 技术实现了视觉语言定位的效率突破。该技术采用并行预测替代传统逐 token 坐标生成,处理速度达到 12.7 框/秒,较自回归方法提升 10 倍,在开放目标检测、OCR、GUI 元素识别等场景中表现优异。模型支持图像/视频全域定位及自然语言指代,显著改善定位精度与效率。

AI语音技术已从基础语音合成进阶到跨语言音色克隆新阶段。小米 AILab 开源的 OmniVoice 模型突破传统 TTS 限制,支持600+语言统一建模,实现三大创新:1)3-10 秒音频即可克隆音色;2)通过自然语言指令自定义音色特征;3)跨语言语音克隆,保留原声说多国语言。该技术还支持方言、口音及长文本处理,适用于数字人、有声书等场景,推动 AI 语音跨越语言边界。用户可通过 OpenBay

Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled是一款高性能对话模型,通过知识蒸馏融合多模型优势,在保持27B参数轻量化的同时显著提升推理能力。

【摘要】OpenClaw是一个集成模型、记忆与执行能力的AI系统,能够自动完成多步骤任务。与普通Agent不同,它通过统一运行环境实现任务闭环,用户只需输入指令,系统即可自主调用工具、执行流程。配置时需在OpenBayes平台克隆教程,部署Qwen3.5-9b模型,并通过Token认证。接入飞书需创建应用、配置权限,注入AppID/Secret后启用长连接事件订阅。完成配对后,用户可在飞书直接使用

【摘要】OpenClaw是一个集成模型、记忆与执行能力的AI系统,能够自动完成多步骤任务。与普通Agent不同,它通过统一运行环境实现任务闭环,用户只需输入指令,系统即可自主调用工具、执行流程。配置时需在OpenBayes平台克隆教程,部署Qwen3.5-9b模型,并通过Token认证。接入飞书需创建应用、配置权限,注入AppID/Secret后启用长连接事件订阅。完成配对后,用户可在飞书直接使用