




- @StillTogether
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepAgent是LangChain推出的独立库,用于构建处理复杂多步骤任务的AI代理。它基于LangGraph构建,具备自动规划、文件系统支持和子代理生成三大核心能力。用户需配置API密钥和Python环境后,通过create_deep_agent函数创建代理。代理默认配备任务管理、7种文件系统操作和子代理工具,能自动分解任务、管理上下文并启动专业化子代理。典型工作流程包括规划、研究、上下文管

指每秒浮点运算次数,是衡量硬件性能的指标,表示计算设备每秒能够完成的浮点运算次数。指浮点运算次数,用于描述模型推理过程中需要的计算量,即模型的复杂度。MACs(乘加累积操作数):指模型中乘法和加法操作的总次数。在神经网络中,乘加操作(Multiply-Accumulate)是常见的计算模式,例如在卷积层和全连接层中。1次乘加操作通常被视为2次FLOPs。1 MFLOPS(百万次浮点运算)= 10⁶

摘要:NVIDIA离散GPU架构专为高性能计算设计,采用独立显存和专用Tensor Cores,在多GPU扩展(NVLink/NVSwitch)和AI软件生态(CUDA、cuDNN等)方面占据优势。苹果统一内存架构(UMA)则通过SoC设计实现CPU/GPU内存共享,能效更高且延迟更低,但内存带宽和扩展性受限。Metal/MPS生态正在发展,但主流框架支持仍不如CUDA成熟。性能测试显示,NVID

《解决GCP实例NVIDIA驱动安装失败问题》 摘要:针对GCP云平台使用H100显卡时出现的"NVIDIA-SMI has failed"错误,本文提供详细解决方案。首先需安装linux-headers等依赖项,禁用默认的Nouveau驱动,然后通过官方脚本安装GPU驱动。验证阶段应使用nvidia-smi和lsmod命令检查驱动状态。常见问题包括GPU未被识别、驱动版本不兼

摘要:NVIDIA离散GPU架构专为高性能计算设计,采用独立显存和专用Tensor Cores,在多GPU扩展(NVLink/NVSwitch)和AI软件生态(CUDA、cuDNN等)方面占据优势。苹果统一内存架构(UMA)则通过SoC设计实现CPU/GPU内存共享,能效更高且延迟更低,但内存带宽和扩展性受限。Metal/MPS生态正在发展,但主流框架支持仍不如CUDA成熟。性能测试显示,NVID
摘要:NVIDIA离散GPU架构专为高性能计算设计,采用独立显存和专用Tensor Cores,在多GPU扩展(NVLink/NVSwitch)和AI软件生态(CUDA、cuDNN等)方面占据优势。苹果统一内存架构(UMA)则通过SoC设计实现CPU/GPU内存共享,能效更高且延迟更低,但内存带宽和扩展性受限。Metal/MPS生态正在发展,但主流框架支持仍不如CUDA成熟。性能测试显示,NVID
先构建一个格式确定下来的Result类public class Result<T> {private Integer code;private String msg;private T data;public Result() {super();}public Result(Integer code...
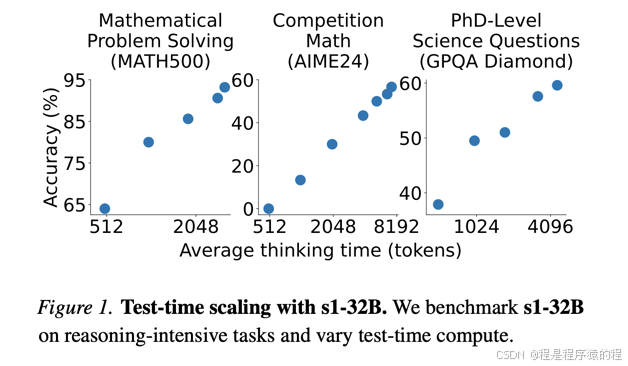
李飞飞团队的 S1 模型展示了一种以极低成本实现高效推理的新路径,其核心在于利用强大的预训练基座、精挑细选的小样本数据集以及创新的测试时扩展技术(如预算强制)。这一方法不仅在实验中获得了与顶尖模型接近甚至超越的成绩,同时也为 AI 模型研发如何在成本与性能间取得平衡提供了有价值的参考。未来能否进一步推广这一方法,还需要在更大范围内验证其通用性和鲁棒性。
在 Chatbox 的设置中,选择使用本地模型,并将模型提供方设置为 Ollama API;对于大多数家用或工作站级别的电脑,运行 1.5b 至 7b 版本已基本满足体验需求,而更高参数的版本则适合服务器或高端工作站使用。:若需要使用模型,只需先启动 Ollama(通常在安装时会自动后台运行),然后通过命令行或图形界面调用模型。下载完成后,在同一命令行窗口中,你可以直接输入问题(例如输入“上海在哪

指每秒浮点运算次数,是衡量硬件性能的指标,表示计算设备每秒能够完成的浮点运算次数。指浮点运算次数,用于描述模型推理过程中需要的计算量,即模型的复杂度。MACs(乘加累积操作数):指模型中乘法和加法操作的总次数。在神经网络中,乘加操作(Multiply-Accumulate)是常见的计算模式,例如在卷积层和全连接层中。1次乘加操作通常被视为2次FLOPs。1 MFLOPS(百万次浮点运算)= 10⁶