




- @Scabbards_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以前整理的模型迭代的对比,自用
以前整理的模型迭代的对比,自用
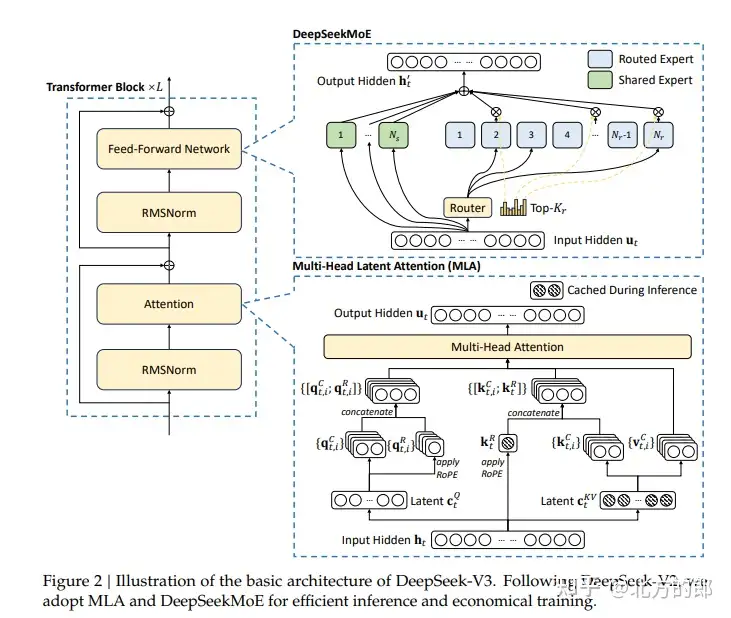
我们将体积(3D)医学图像分割任务重新制定为序列到序列的预测问题。我们引入了一种新的架构,称为UNEt-TRansformer(UNETR),它利用Transformer作为编码器来学习输入体积的序列表示并有效捕获全局多尺度信息,同时也遵循编码器和解码器的成功“u形”网络设计也能很好的提取到局部特征。
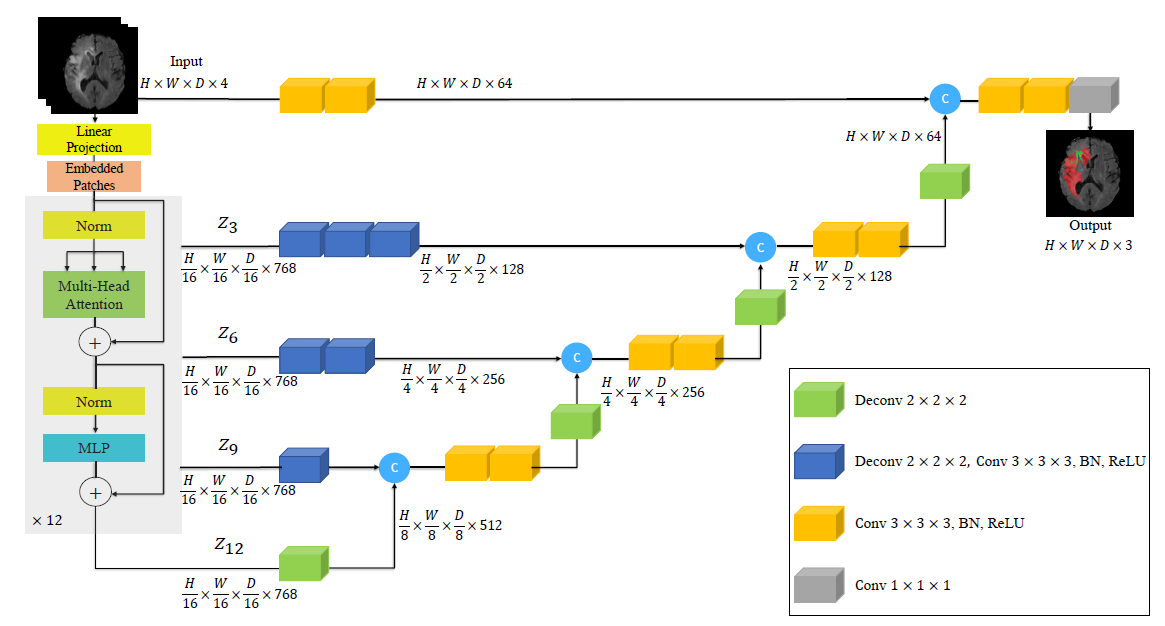
我们提出了一种新的分割任务-推理分割。该任务的目的是在给定复杂且隐式的查询文本的情况下输出分割mask。此外,我们建立了一个由一千多个图像指令对组成的基准,将复杂的推理和世界知识纳入评估目的。最后,我们提出了LISA:大型语言指导分割助手,它继承了多模态大型语言模型(LLM)的语言生成能力,同时还具有生成分割掩码的能力。LISA可以处理以下情况:1)复杂推理;2)世界知识;3)解释性答案;4)多回
模型推理速度和吞吐量,算Inference Speed (in ms)的!

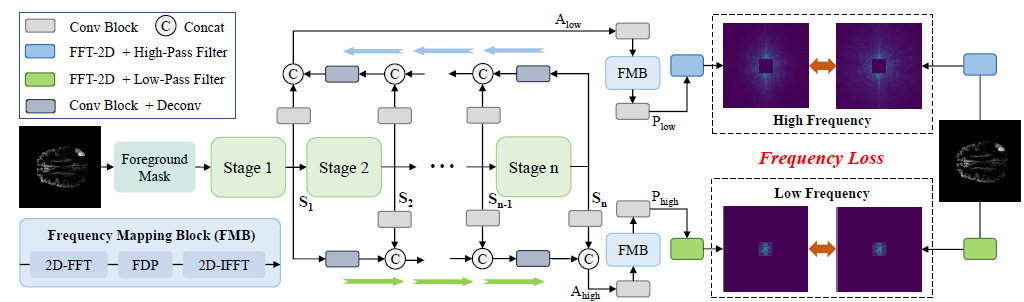
为了将关键的全局结构信息和局部细节信息结合到密集预测任务中,我们将视角转移到频域,提出了一种新的基于mimm的自监督预训练框架FreMIM,以更好地完成医学图像分割任务。在观察到详细的结构信息主要存在于高频成分中,而低频成分中高层次语义丰富的基础上,我们进一步在预训练阶段引入多阶段监督来指导表征学习。
记录一下阿里云 mcp 平台上架自己的mcp
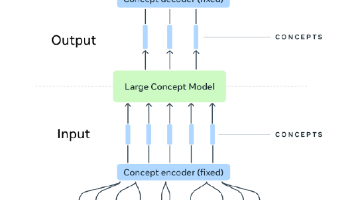
Meta引入了大型概念模型(Large Concept Models, lcm),代表了传统的基于令牌的框架的重大转变。lcm使用概念作为理解的基本单位,支持更复杂的语义推理和上下文感知决策。鉴于这一新兴技术的学术研究有限,我们的研究旨在通过收集、分析和综合现有的灰色文献来弥补知识差距,以提供对lcm的全面了解。具体来说,我们(i)识别和描述LCM与llm的区别特征,(ii)探索LCM在多个领域的
我们描述了一种简单的无监督域自适应方法,即通过交换源和目标分布的低频频谱来减小源和目标分布之间的差异。我们在语义分割中说明了该方法,其中密集注释的图像在一个领域(例如,合成数据)中很丰富,但在另一个领域(例如,真实图像)中很难获得。目前最先进的方法是复杂的,一些需要对抗性优化,以使神经网络的主干对离散域选择变量保持不变。我们的方法不需要任何训练来执行域对齐,只需要一个简单的傅里叶变换及其逆变换。尽
