




- @Prototype___
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
单位最近也接入了满血版DeepSeek用于业务系统,不过单一智能体的表现并不能够完全符合生产环境,所以对大语言模型下的多智能体协作机制进行研究,随着大语言模型(LLMs)的不断发展,代理式人工智能(Agentic AI)在现实应用中取得了显著进展,推动了基于多个大语言模型的智能体系统的发展,使其具备感知、学习、推理和协同执行任务的能力。这些基于大语言模型的多智能体系统(MASs)能够通过智能体间的

单位最近也接入了满血版DeepSeek用于业务系统,不过单一智能体的表现并不能够完全符合生产环境,所以对大语言模型下的多智能体协作机制进行研究,随着大语言模型(LLMs)的不断发展,代理式人工智能(Agentic AI)在现实应用中取得了显著进展,推动了基于多个大语言模型的智能体系统的发展,使其具备感知、学习、推理和协同执行任务的能力。这些基于大语言模型的多智能体系统(MASs)能够通过智能体间的
D3可以实现更加灵活且富有变化的图形。在使用Echarts的配置项就可以完成绘图,而D3需要自己造轮子,手动实现可视化的每一处细节,虽然门槛更高、难度更大,但是使用起来更加灵活自由,能够实现更为复杂多样的可视化效果。通过此次项目使用D3的选择DOM元素和绑定数据,数据添加、更新DOM元素的操作,使用D3一般遵循以下流程
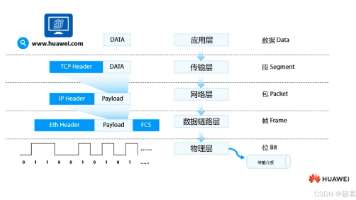
数据封装过程被形象比喻为快递打包,详细说明了从应用层到物理层的五层封装(数据→段→包→帧→比特流)及对应的解封装过程。传输介质部分对比分析了有线介质(双绞线、同轴电缆、光纤)和无线介质的特点,重点强调了光纤在高速网络中的优势及单模/多模光纤的应用场景。文章最后指出这些知识对HCIP认证考试和实际网络设计的重要性,强调要根据具体需求选择合适的传输介质。通过生活化类比使复杂的网络概念更易理解。
动态主机配置协议(DHCP) 是一种用于自动分配IP地址和其他网络参数的网络协议。它通过客户端/服务器模式工作,客户端向服务器请求配置信息,服务器根据策略返回相应的信息,如IP地址、子网掩码、网关和DNS服务器地址。DHCP的配置非常简单,以新华三设备为例,在交换机、路由器的三层接口上去配置这个功能就好了。比如交换机使用vlanif作为三层接口,配置就这些操作,开启DHCP服务功能,开完之后针对地

ACL由若干条pemit或deny语句组成。每条语句就是该ACL的一条规则,每条语句中的permit或deny就是与这条规则相对应的处理动作。基于ACL规则定义方式的分类。基于ACL标识方法的分类。

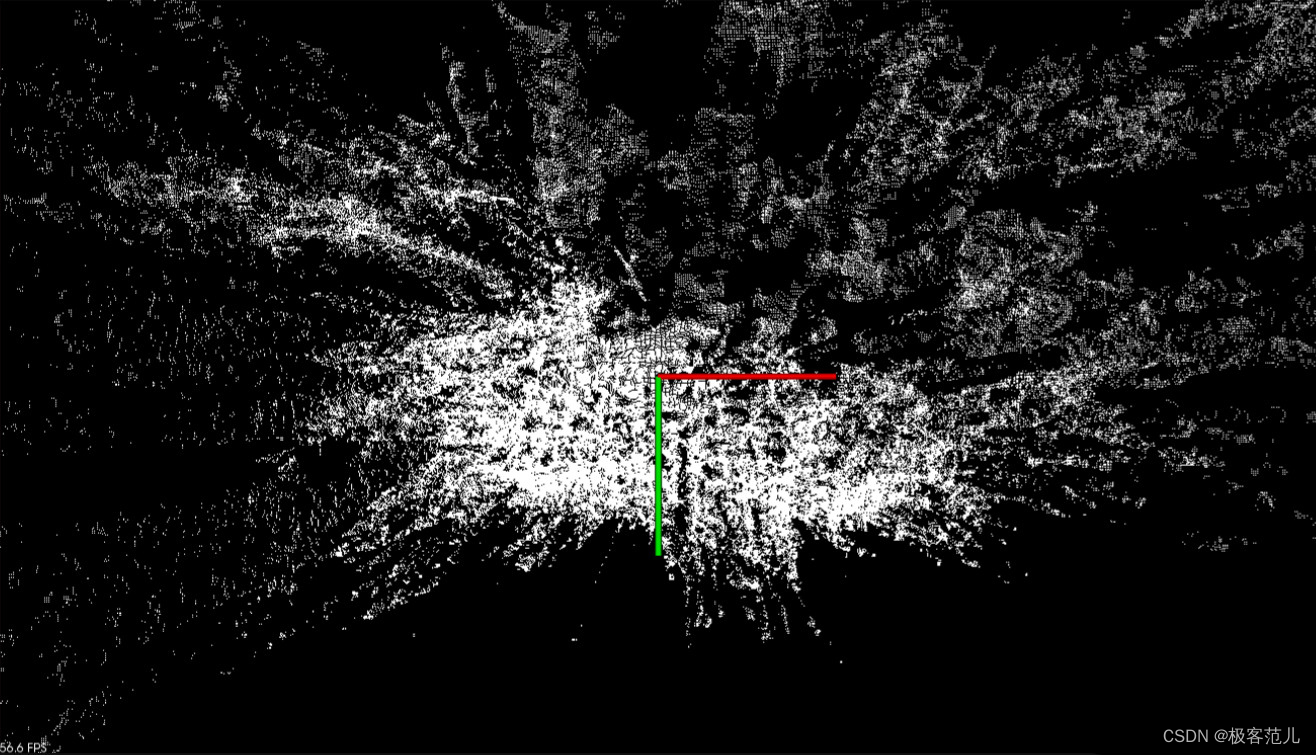
目前最近的SDK版本是1.4.2,这个相机成本便宜,有硬同步的IMU,频率也够高,自带标定,对于目前我只做视觉SLAM定位足够用了。然而封库,其他各种依赖库要跟着SDK的库,OpenCV不使用ROS自带的版本,使用单独版本3.4.3等等。这个SDK组织得真的是一言难尽,所以分析SDK中实时显示点云图代码并加以改进,记录下学习的过程。
D3可以实现更加灵活且富有变化的图形。在使用Echarts的配置项就可以完成绘图,而D3需要自己造轮子,手动实现可视化的每一处细节,虽然门槛更高、难度更大,但是使用起来更加灵活自由,能够实现更为复杂多样的可视化效果。通过此次项目使用D3的选择DOM元素和绑定数据,数据添加、更新DOM元素的操作,使用D3一般遵循以下流程
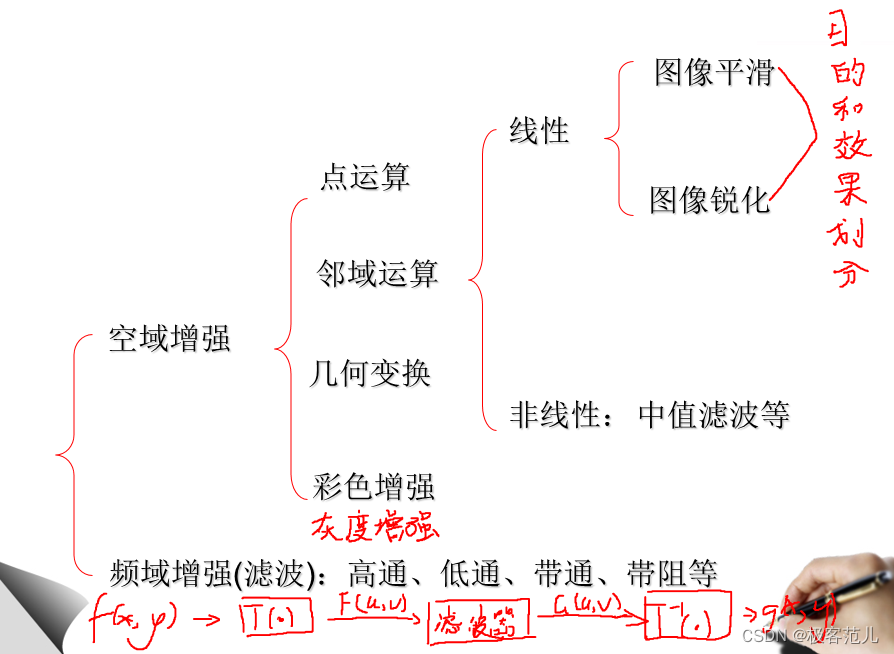
最近科研需要改进算法,需要先对图像进行增强后处理,所以对图像增强技术做一个总结。图像增强的目的就是要提高图像的质量,在图像处理中,有两种提高图像质量的方法:一是图像在采集的过程中,知道图像质量降低的原因,根据原因进行图像恢复,图像复原等处理,二是不管图像质量降低的过程,针对图像本身增强,后者就是本文讨论的内容。图像增强处理技术基本上可以分成两大类,一类是空域处理方法,一类是频域处理方法。
导师让我了解SLAM,SLAM原本是比较小众的方向,最近自动驾驶火起来,做这个SLAM的人也多了,反过来也会推动机器人感知的发展。希望未来学成的时候,能赶上机器人大规模普及,就业一片蓝海。关于视觉SLAM我感觉学习成本高、科研选题难和行业壁垒高,但是充满挑战不是很有意思嘛。学SLAM方向跟motion planning科研都不好做,而且都很吃数学基础。学习难度的话,planning可能教程更多一点
