




- @Maxwell_li1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
全连接层中每个神经元与上一层所有神经元相连。公式:其中( W ):权重矩阵( b ):偏置向量( x ):输入向量( y ):输出向量多通道输入 → 每个卷积核对每个通道单独卷积 → 结果求和 → 输出一个特征图。GAN = 生成器(造假) + 判别器(识假)通过对抗训练,让模型学会**“创造真实感数据”**。
Pandas数据分析完整指南摘要 Pandas是Python核心数据分析库,提供Series和DataFrame两种核心数据结构。本指南系统讲解: 基础数据结构:Series(一维带标签数组)和DataFrame(二维表格)的创建与操作 数据处理:包括字符串操作(strip/split/replace等)、索引访问、属性查询 高级特性:继承NumPy的向量化运算、统计函数应用 数据I/O:支持多种

2026年3月,美军用AI在24小时内打击逾千个目标,一场关于"谁来定义AI价值观"的权力博弈同步爆发。从商业公司悄悄删除安全条款,到AI模拟战争中本能选择核武器,再到联合国限武截止日期在沉默中滑过——本文还原那条从人类底线价值观到AI实际行为之间的传导链,究竟在哪里断裂。烟花与枪火本质上都是火。AI全面渗入生活的此刻,真正的问题只有一个:这个工具,在替谁说话?

全连接层中每个神经元与上一层所有神经元相连。公式:其中( W ):权重矩阵( b ):偏置向量( x ):输入向量( y ):输出向量多通道输入 → 每个卷积核对每个通道单独卷积 → 结果求和 → 输出一个特征图。GAN = 生成器(造假) + 判别器(识假)通过对抗训练,让模型学会**“创造真实感数据”**。
Pandas数据分析完整指南摘要 Pandas是Python核心数据分析库,提供Series和DataFrame两种核心数据结构。本指南系统讲解: 基础数据结构:Series(一维带标签数组)和DataFrame(二维表格)的创建与操作 数据处理:包括字符串操作(strip/split/replace等)、索引访问、属性查询 高级特性:继承NumPy的向量化运算、统计函数应用 数据I/O:支持多种
Pandas提供了强大的数据合并功能,主要包括堆叠合并(concat)和主键合并(merge)两种方式。堆叠合并分为横向堆叠(axis=1)和纵向堆叠(axis=0),前者用于增加列特征,后者用于增加行记录。concat函数支持多种参数设置,包括合并方向、连接方式(outer/inner)、索引处理等。在实际应用中,合并前需注意索引对齐问题,避免产生NaN值。典型应用场景包括合并不同时间段或不同部
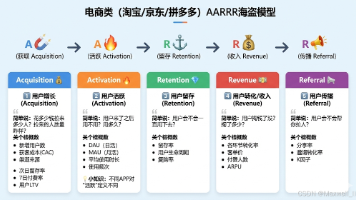
商业数据分析指标体系摘要 本文系统梳理了五大类互联网产品的核心数据分析指标体系: 电商类:基于AARRR模型,涵盖用户增长、活跃、留存、转化和传播全链路指标 内容资讯类:围绕内容生产、分发、消费、互动和变现构建闭环评估体系 社交类:聚焦关系建立、内容互动、用户留存和商业变现四个维度 工具类:从工具价值、使用效率、用户依赖、场景延伸和商业变现评估产品价值 游戏类:贯穿新手引导、核心玩法、社交系统、付
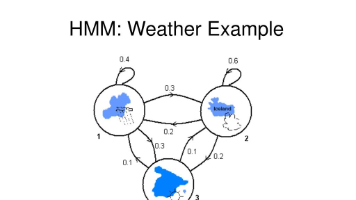
HMM前向算法通俗解析 本文用生活化例子直观讲解隐马尔可夫模型(HMM)的前向算法。通过"天气-打伞"的类比,将复杂的数学公式转化为容易理解的动态过程:算法通过逐日计算三种天气状态(晴/阴/雨)的可能性,考虑前一天所有可能的转移路径,并乘以当前观测(打伞/不打伞)的概率。最终将所有可能路径的概率相加,得到整个观测序列出现的总概率。核心思想可概括为:当前状态概率=(前一天各状态转
本文整理了SQL中自定义函数与存储过程的核心知识点。自定义函数用于返回单一值,适合简单计算和数据转换;存储过程处理复杂业务逻辑,可返回完整结果集。文章详细介绍了两种方法的创建语法、调用方式及典型应用场景,并通过具体示例展示了它们的使用方法(如价格计算、条件打折等)。关键区别在于:函数通过RETURN返回值,存储过程通过SELECT返回结果集;函数嵌入SELECT调用,存储过程用CALL调用。本文还