
写文章




- @Je1zvz
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务

【论文学习3】LDAM:Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
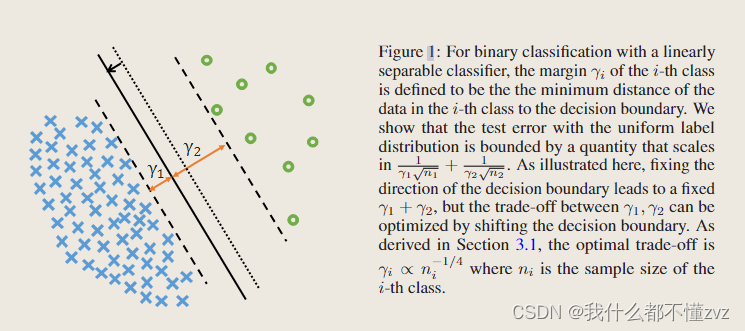
训练数据集出现严重的类不平衡问题会导致在实际应用中缺乏泛化性。该文设置了两种解决的算法:1)基于标签分布的边界损失(Label-distribution-aware margin, LDAM);2) 延迟重新加权(Defers re-weighting, DRW),既让模型学习初始特征表示,再进行re-weighting或re-sampling。
【论文学习1】Deep Long-Tailed Learning: A Survey
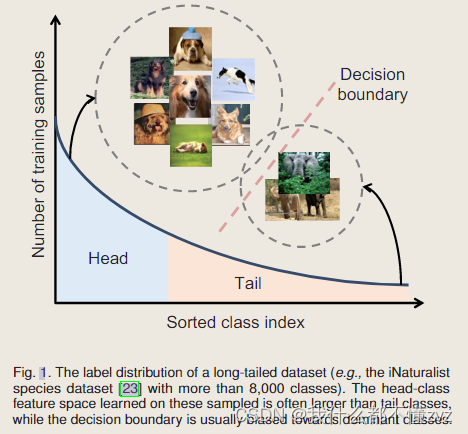
训练数据通常存在长尾类别分布问题,既小部分类中拥有大量的样本点,大部分类中拥有少量的样本点。这样会限制深度学习模型的实用性,由这样数据集训练出来的模型往往不会在现实实际应用表现得很好,因为它们会更倾向于主导类,并在尾部类表现得很差。如下图所示,大量数据在少数类里;总的来说,有两大挑战:1)不平衡导致模型偏向于头类;2)缺乏尾类使得训练模型进行尾类分类更具挑战;不平衡比的定义:n1nkn_1/n_k
到底了