- @Gorege__Hu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(稍微了解即可,一般不会涉及)在一个图里每条边都有一个权值(有正有负)如果存在一个环(从某个点出发又回到自己的路径),而且这个环上所有权值之和是负数,那这就是一个负权环,也叫负权回路。存在负权回路的图是不能求两点间最短路的,因为只要在负权回路上不断兜圈子,所得的最短路长度可以任意小。含有负权重的无向图都是负权回路。例如下图,可以在2‐3之间无限循环。注意:贝尔曼‐福特算法实际上处理的是具有负权重的
整个逻辑是这样,通过mavros_posix_sitl.launch生成地图,然后该launch文件中通过参数sdf选择iris_3d_lidar_360无人机,launch文件通过iris_3d_lidar_360.sdf文件将无人机加载进地图,而无人机的sdf文件又用include来引入了Mid360模型,通过Mid360文件夹下的Mid360.sdf再将mid360雷达加入无人机上,最终搭配
ADC模数转换器就是将变化的模拟量转化成变化的数字量的器件。打开《CT117E-M4产品手册》第10页可以看到这部分的电路图可以看到PB15和PB12分别通过J11和J12两个跳线帽连接到R37和R38两个旋转定位器上。从而可以将电阻的分压值从0~VDD(3.3V)进行调节。STM32G431内部集成有2个最高12位的ADC(ADC1和ADC2)。在《STM32G4系列微控制器参考手册》中可以查看
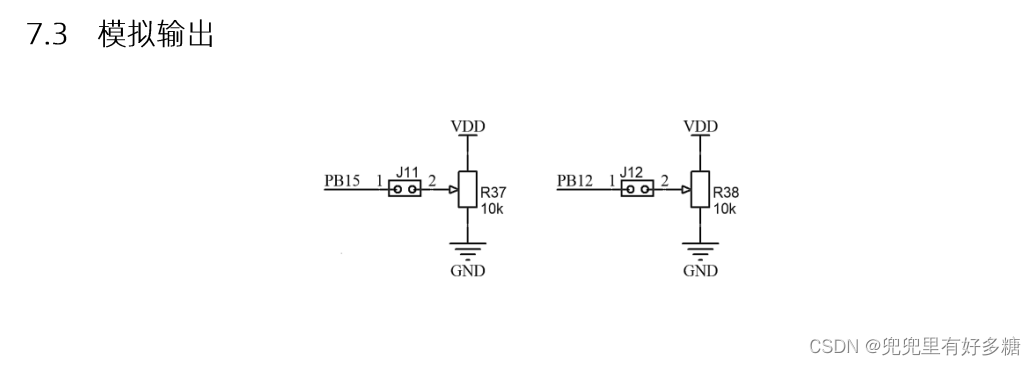
ADC模数转换器就是将变化的模拟量转化成变化的数字量的器件。打开《CT117E-M4产品手册》第10页可以看到这部分的电路图可以看到PB15和PB12分别通过J11和J12两个跳线帽连接到R37和R38两个旋转定位器上。从而可以将电阻的分压值从0~VDD(3.3V)进行调节。STM32G431内部集成有2个最高12位的ADC(ADC1和ADC2)。在《STM32G4系列微控制器参考手册》中可以查看
AirSim的使用着实是一件麻烦事,我的配置过程可谓是坎坷重重。原因在于AirSim对于电脑要求较高,所以即使我手头有一个Interl mini PC,但是由于没有独立显卡,也没有办法实现在Ubuntu环境下使用AirSim。而电脑又不太想装双系统,并且在VMware虚拟机里面没有办法使用电脑的独立显卡,因此也不能使用AirSim。
ADC模数转换器就是将变化的模拟量转化成变化的数字量的器件。打开《CT117E-M4产品手册》第10页可以看到这部分的电路图可以看到PB15和PB12分别通过J11和J12两个跳线帽连接到R37和R38两个旋转定位器上。从而可以将电阻的分压值从0~VDD(3.3V)进行调节。STM32G431内部集成有2个最高12位的ADC(ADC1和ADC2)。在《STM32G4系列微控制器参考手册》中可以查看
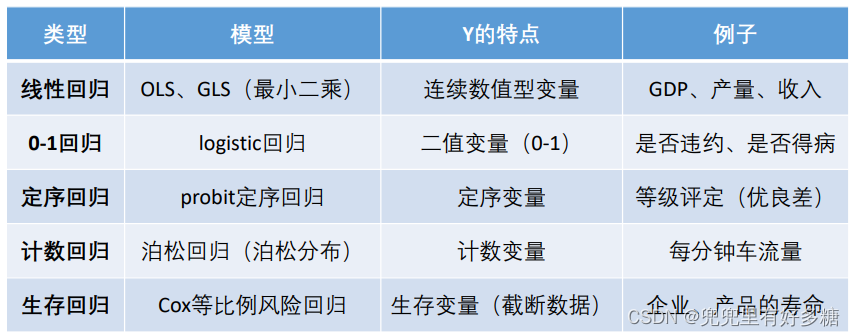
(5)研究产品寿命、企业寿命甚至是人的寿命(这种数据往往不能精确的观测,例如现在要研究吸烟对于寿命的影响,如果选取的样本中老王60岁,现在还活的非常好,我们不可能等到他去世了再做研究,那怎么办呢?简而言之:如果我们的模型考虑的自变量不全,会导致本来不是自变量的干扰项μi带有某些我们没有考虑进去的自变量的变化规律,这样导致的问题就是对我们已考虑的自变量的回归系数的评定影响会很大,不满足无偏性和一致性