- @Foolforuuu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在之前的文章,我们为大家解释了 HPC 高性能计算的概念。随着技术的发展和数据量的爆炸性增长,企业面临的挑战日益复杂,对计算能力的需求也在不断增加。这些问题的解决超出了传统计算方法的能力范围,高性能计算(HPC)正是为解决这类问题而生。HPC 能够提供巨大的计算能力,处理复杂的数据和高级模拟,这对于需要执行大量计算的任务非常关键。在科学研究、工程设计、金融分析等领域中,HPC 已经成为推动创新和效

在当今数字化和信息化迅速发展的时代,高性能计算(HPC)已成为各行各业的关键技术支撑。HPC 涉及使用超级计算机及高效算法来解决复杂的科学、工程和商业问题。HPC 的核心价值在于其强大的数据处理能力,能够在极短的时间内处理和分析大量数据。下面,根据自身的落地经验与行业趋势,总结概述高性能计算 HPC 在各行各业的应用。在生命科学领域,客户的本地计算资源虽能满足常规需求,但在研究高峰和突发大数据处理

一晃眼,好几年都过去了,上次聊这个话题,Apple 还只有 M1 处理器,现在都更新到了 M4。现在芯片厂的最新趋势都是异构计算,集成到一个芯片里面。中央处理器(CPU)、图形处理器(GPU)、神经网络处理器(NPU)能够各司其职。CPU主要应对顺序控制和即时性运算,适用于需要低时延的应用场景;GPU擅长面向高精度格式的并行数据流处理,比如对画质要求非常高的图像以及视频处理;NPU则更擅长与AI运

上周写了一篇文章,讲大模型两种模式,一种是 Copilot,一种是 Agent。

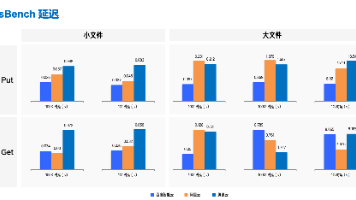
本次测试对市面上场景的几家云厂商的对象存储产品,包括阿里云(OSS)、百度智能云(BOS)和腾讯云(COS),对象存储产品性能进行了全面评估。通过 cosbench 工具测试可以相对公平反应各家对象存储的实际性能。综合测试结果,可以大致得到以下结论:百度智能云 > 阿里云 > 腾讯云阿里云(OSS):综合能力处于中等水平,10M-100M 的文件延迟较差,其他常见场景如小文件的延时还是大文件的吞吐
标题先上结论,为啥这么认为,且听接下来道来。snowflake 非常成功,开创了云数仓先河,至今在数仓架构上也是相对比较先进的,国内一堆模仿的公司,传统上我们会认为 snowflake 肯定是一家数据仓库公司。不过最近这个认知被颠覆了。最近 youtube 上看了2024 snowflake summit,snowflake 搞了一大堆发布,主要做了三大块:1、数据(数仓,BI,分享)2、开发(构

云数据库和本地数据库的区别

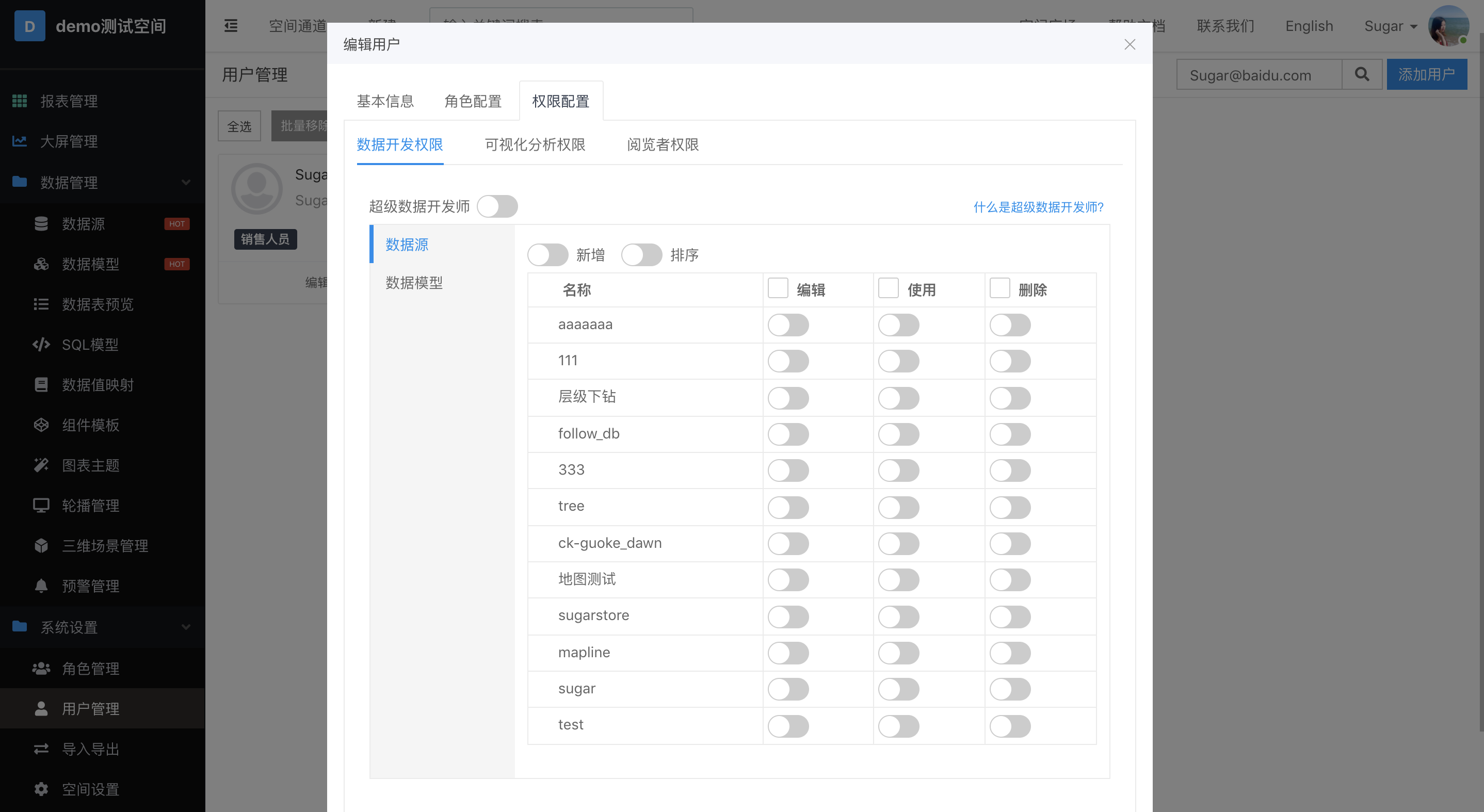
数据开发权限、可视化分析权限和阅览者权限,涵盖了Sugar BI中各类资源的操作权限控制。这三类权限可以任意组合使用,并且每类权限中都有一个超级权限的开关,方便您可以快速设置权限。
Sugar BI中的两个页面之间可以使用下钻来进行跳转,并且在 A 页面进行下钻的时候可以附带上一些下钻的参数,跳转到 B 页面后,B 页面中的内容(如图表的数据、地图的区域)可以根据 A 页面带过来的下钻参数进行动态的切换,一个经典的分析场景如全国的销售概览和各省份销售数据之间的下钻联动分析

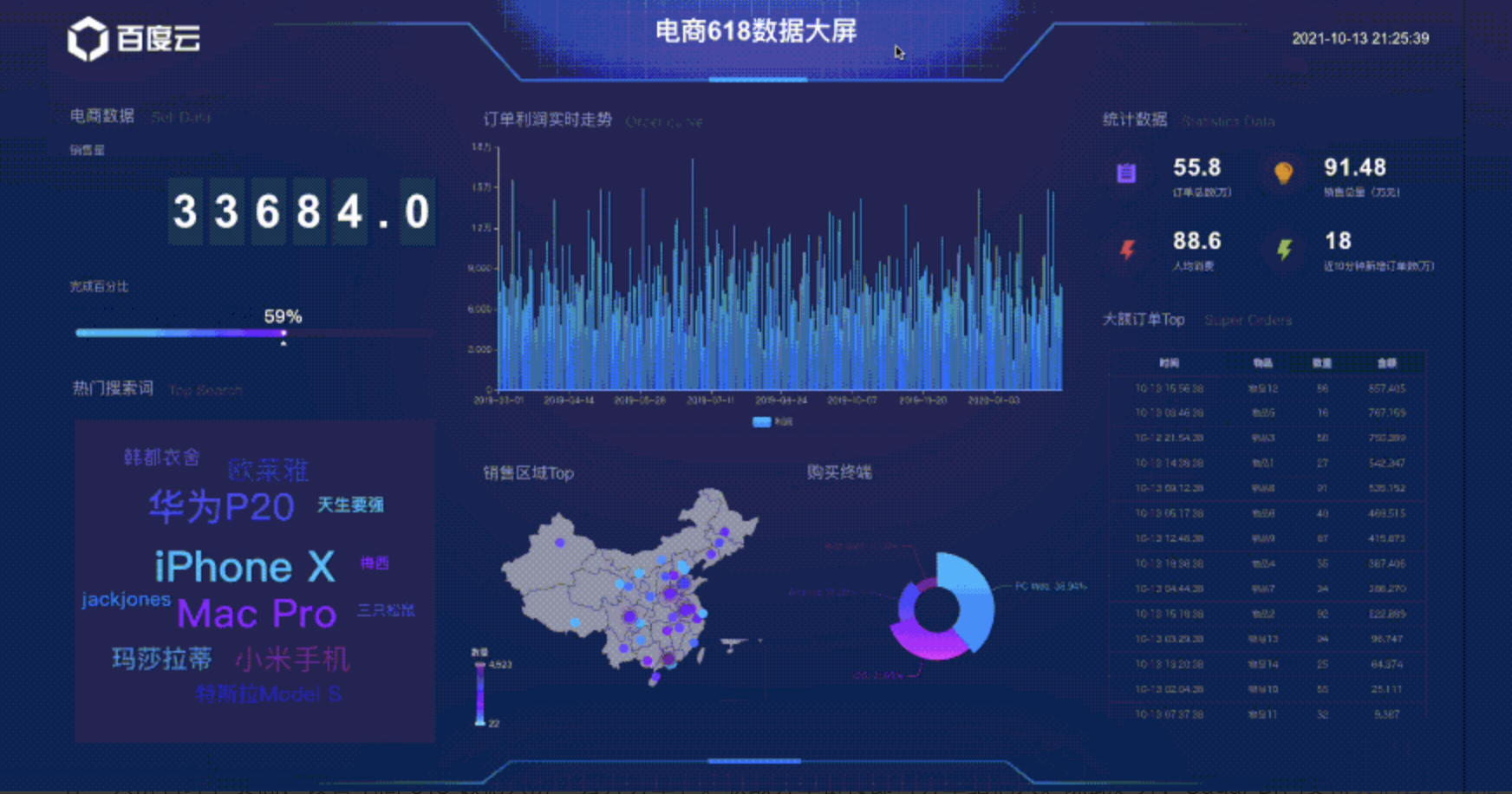
数据可视化大屏可以在企业的某些特定大场景中直接、美观地将关键数据信息融合在一个屏幕中进行及时展现,在现实中应用广泛。在日常企业的运作与业务运营中,可能使用到数据可视化大屏的典型应用场景,大概有以下几个:电商 618 数据大屏企业实时销售数据概览大屏IT 实时监控大屏政务领导驾驶舱交通概览一张图等等.......这些数据可视化大屏的应用场景主要用于实时同步重点指标和图表,方便目标受众根据实时数据,动