




- @Flag_ing
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文记录在 jetson orin nx 上使用 ollama 部署 deepseek 的过程。

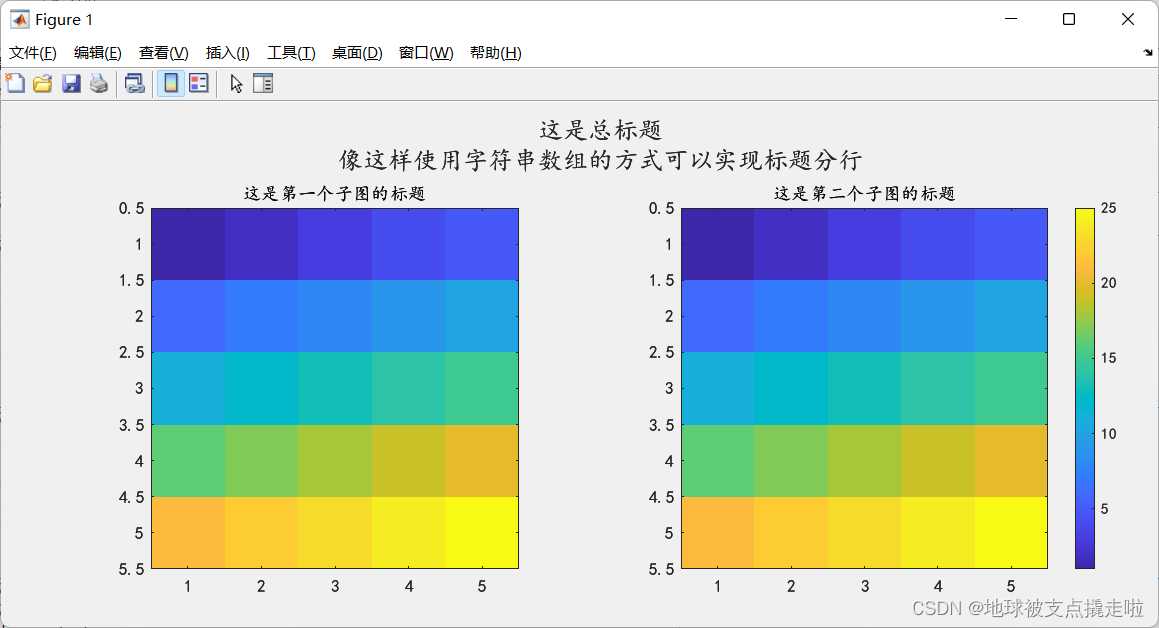
当遇到需要查看一个二维矩阵数据中值的大小分布情况时可以使用 MATLAB 把矩阵以图像的形式展现出来,这样更直观。MATLAB 的可视化函数之一是,还有其他的方法,这里只介绍下 imagesc。
本篇记录了自己刚拿到Jetson板子后,刻意去学习给板子重刷系统的过程,。注意:我使用的是 Nvidia 官方给 Jetson 刷系统的,需要(双系统或者虚拟机都可)用来运行 SDK Manager,然后通过USB 线连接到 Jetson,实现给 Jetson 刷系统。

【代码】ubuntu22.04 install NVIDIA driver。

还以目标检测为例,仍然拿一个很大的数据集来训练模型,而 meta-learning 的目标不是让模型在没见过的图片中学会分辨训练集中提到过的类别,而是让模型学会分辨事物的异同,学会分辨这两者是相同的东西还是不同的东西,当模型学会分辨异同之后再在具体的分类任务中使用极少的数据集训练很少的次数即可达到甚至超越传统目标检测训练范式的效果(这种方式也称为。以上是元学习在目标检测方面的一种应用,通过元学习训

问题:在VSCode 中使用 Run Code 运行 python 程序 会出现以下乱码:原因:没有设置 python 的编码格式问题解决:在 file—Preferences——Settings 中找到 Run Code configuration——Edit in settings.json,如下在打开的 json 文件中查看是否有"code-runner.executorMap":{...}
目录1、创建空列表2、索引、切片3、加入元素4、删除、清空操作5、列表长度及最值6、运算符和表达式7、值的索引8、反转及排序9、统计指定元素出现的次数10、列表相互赋值(理解浅拷贝)python 中的列表(list)类型类似于 C++ 中的 vector 类型,不过列表的功能更多。1、创建空列表直接使用一对空的方括号就可以创建空列表alist = []列表中的元素类型不必都相同,比如下面的例子中,
用惯了Windows下的有道词典,其划词翻译功能用起来令人极其舒适。Linux下也有类似的软件:GoldenDict安装:sudo apt-get install goldendict下载之后找到图标,打开后如下所示:下面开始简单的配置一下GoldenDict:...
目录0、IOU 的原始计算方式1、GIOU(Generalized IOU)2、DIoU(Distance-IoU)3、CIoU(Complete-IoU)IoU 即 Intersection over Union 中文叫做交并比,用来衡量目标检测过程中 预测框 与 真实框 的重合程度。目前有很多计算 IoU 的方法,这里主要介绍 GIOU、DIOU、CIOU 这三种方式。...
函数定义:DataFrame.sample(self: ~ FrameOrSeries, n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)作用:从所选的数据的指定 axis上返回随机抽样结果,类似于random.sample()函数。举个栗子(关于每个参数的解释在最下面):1、首先定义一个数据