写文章




- @AwesomeP
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
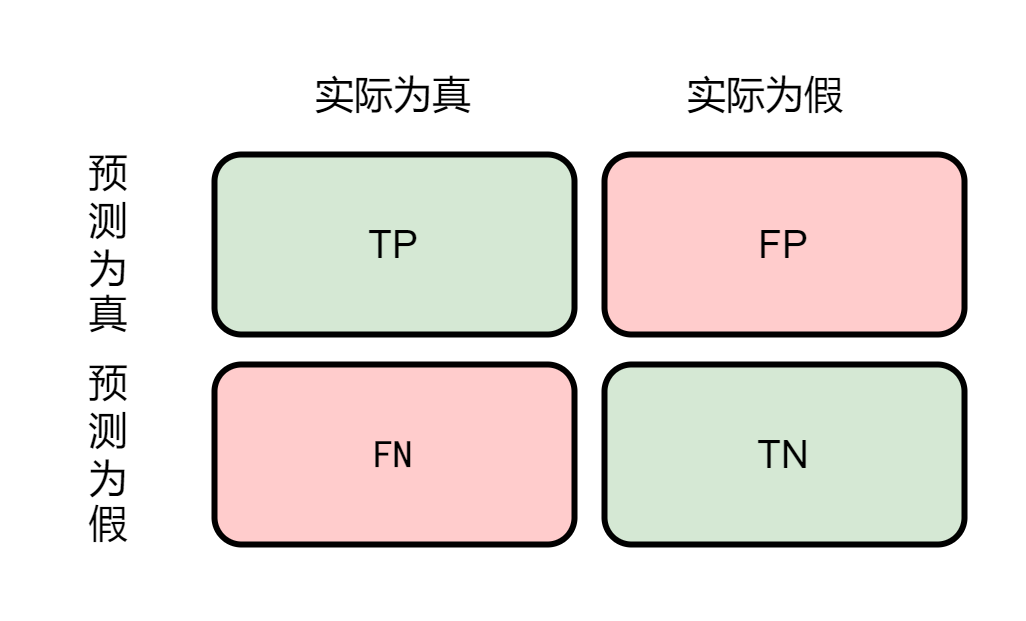
【机器学习】二分类问题中的混淆矩阵、准确率、召回率等 (Python代码实现)
二分类问题中的混淆矩阵、准确率、召回率、Acc的介绍及代码实现
Karpathy Guidelines:让 AI 写出更好代码的 4 条行为准则
Karpathy Guidelines:AI编程的4条黄金准则
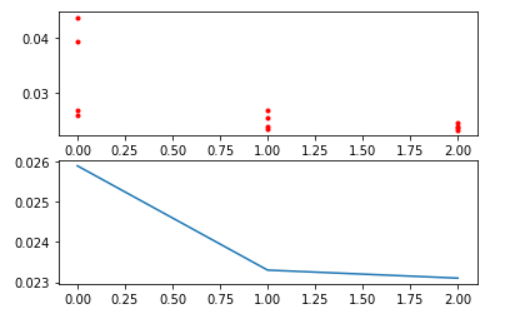
【优化算法】使用遗传算法优化MLP神经网络参数(TensorFlow2)
使用遗传算法对神经网络参数进行优化,提高深度学习模型的准确率。(Python、TensorFlow2、scikit-opt)
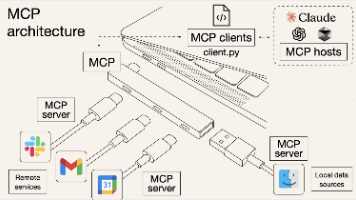
MCP-Rules-Skills入门指南
Agent中常用的MCP/Skills/Rule介绍
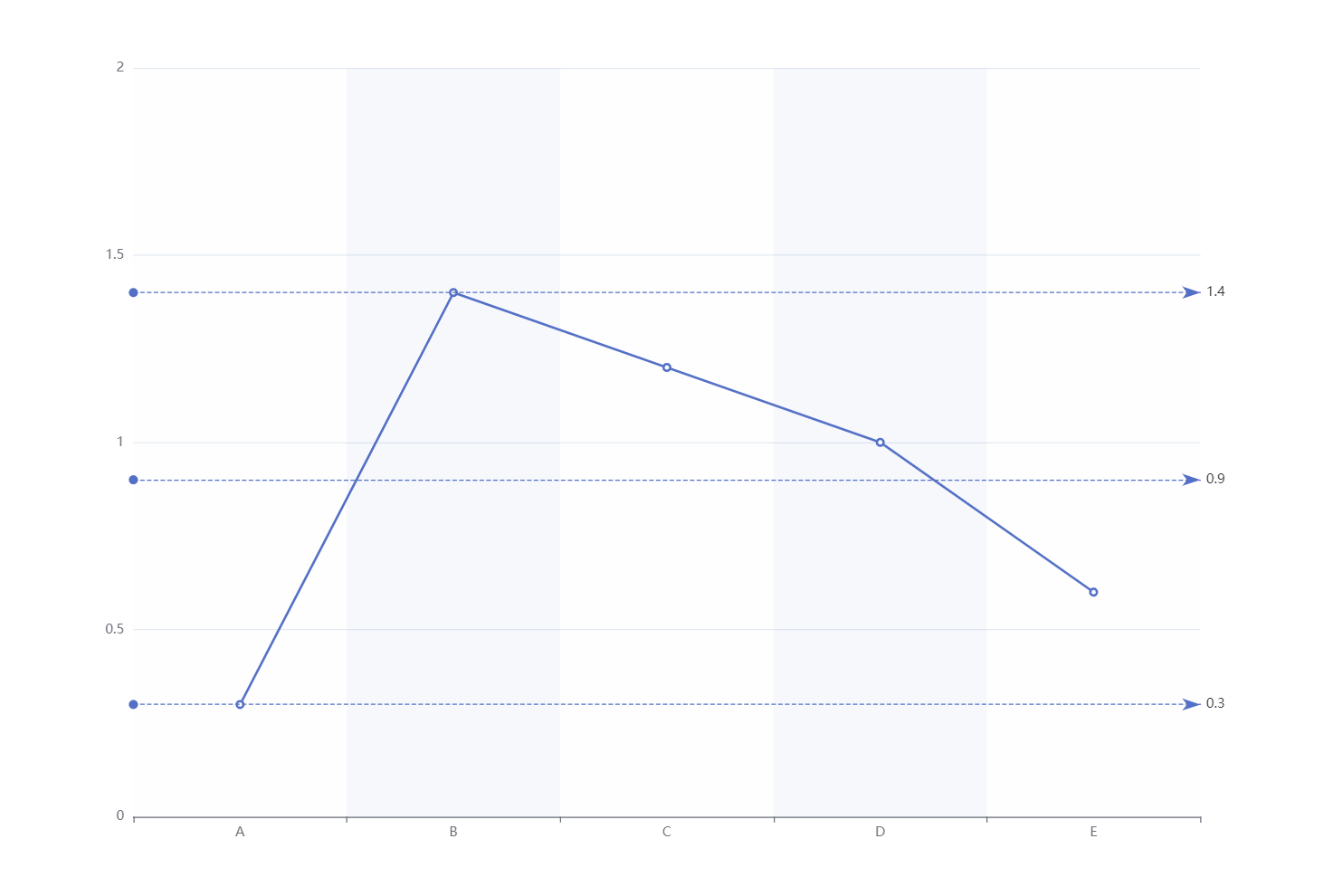
【前端】echarts折线图中画水平参考线辅助线
使用markline在echart折线图中画水平参考线
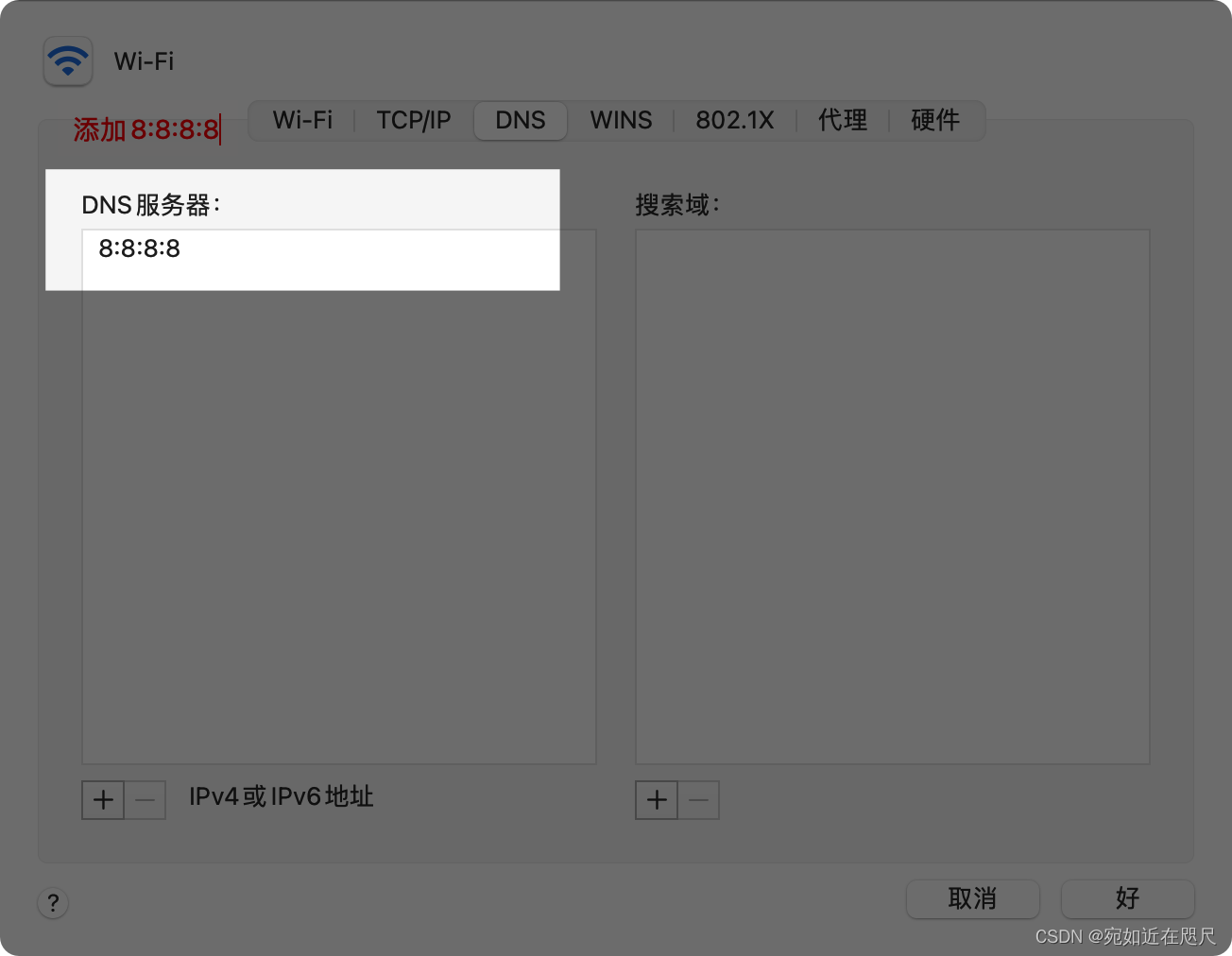
Mac终端出现@bogon的解决办法(恢复以前方法)
因强制关闭终端等原因,再次打开后发现终端出现bogon字样,之前的某某deMacBook-Pro被替换。
【迁移学习】猫狗数据分类案例(TensorFlow2)
2 数据处理共2000张猫狗图片数据集,下载地址:Kaggle dc_20003 创建模型,使用VGG16作为预训练模型输出:4 训练模型
MCP-Rules-Skills入门指南
Agent中常用的MCP/Skills/Rule介绍
【生成对抗网络】GAN入门与代码实现(二)
上篇博客:生成对抗网络GAN入门与代码实现(一)本篇主要介绍简单GAN的另一种实现方法(不使用卷积),依然使用TensorFlow2进行搭建,主要运用了TensorFlow2中的求导机制进行自定义训练,自由度更高。对比上篇博客中的实现方法可加深对GAN的编写理解。文章目录1 导包2 数据准备3 生成器模型4 判别器模型5 编写损失函数,定义优化器6 获取模型&定义训练批次函数7 定义可视化
【Prompt工程】让大模型生成软件开发代码
大语言模型万能提示词模版及开发应用案例分享