




- @Appen_China
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
具身智能正成为下一代AI发展核心,但面临高质量多模态数据不足的挑战。本期推荐两大核心数据集:1000小时机械臂遥操数据集(覆盖多场景任务,含多模态同步数据)和第一人称手部操作数据集(专业场景动作捕捉)。这些数据从通用智能形成、环境适应性及任务迁移三个维度,助力攻克跨模态融合、动态适应等瓶颈。澳鹏提供800+成品数据集,支持80+语言,持续为AI模型训练提供高质量数据解决方案。

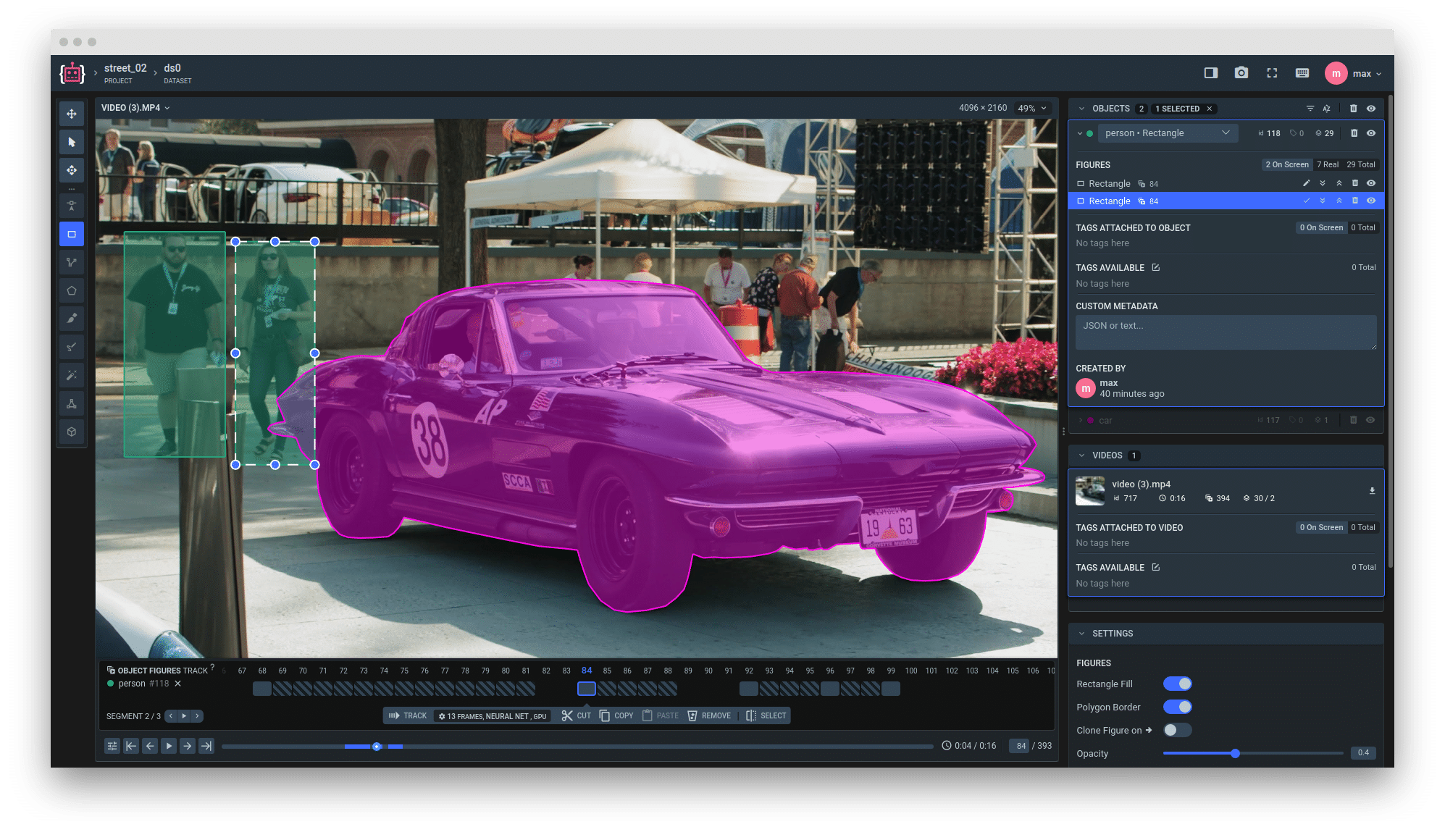
本文基于具身智能数据采集的实际项目经验,系统分析了UMI入户采集、Ego第一人称视角采集及遥操数据采集面临的三大核心难点:场景资源稀缺且非标、采集效率瓶颈、数据多样性与质量挑战。针对性地提出了“基地模拟+入户采集+实体工厂”的场景覆盖策略、“流程优化+人力保障”的效率提升方案以及“数据质量与多样性管控”的端到端实践路径,并展示了关键数据指标。

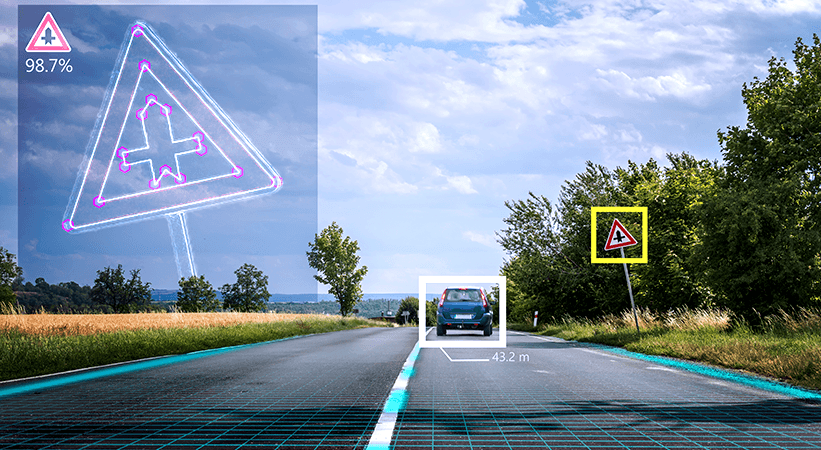
到了1978年,麻省理工学院人工智能实验室的研究人员开发了一种自下而上的方法,从二维计算机生成的“草图”中推断出三维模型,至此,计算机视觉的实际应用才变得显而易见。计算机视觉和机器视觉均利用图像捕捉和分析,其执行任务的速度和精确度是人眼无法比拟的。有鉴于此,用这两种密切相关的技术的共性来描述二者,用它们的特定用例而不是它们之间的差异来区分二者,可能会更有成效。有一些公共使用的免费数据集可以很好地用
明确了解测试目标。定义测试的具体领域,包括范围内和范围外危害类型或攻击策略的具体参数。
目前,相关机构正在开展研究,旨在通过更好地了解滋生虐待老人案件的环境条件,并利用这些信息预测最有可能出现哪类虐待,从而提前预防虐待老人案件,防患于未然。它们可以进入危险的场所,识别带来潜在威胁的人和物,相比警察冒着生命危险进入这些场所,机器人无疑是更安全的替代方案。借助增强型图像技术与物体和人脸识别技术,AI 能够减少执法部门对劳动密集型任务的需求,进而释放警察的精力,使其能够执行更复杂的工作。此

案例中,他们的机器旨在简单地扫描货架,寻找库存不足的商品,同时识别错误的定价,然后将此信息与人类工作人员共享,提醒他们商店的哪些区域需要优先补货。这些机器的目标是不让任何商品出现缺货,因为货架一旦出现缺货,消费者可能无法买到所需之物,这无疑会降低销售额。过去几年,如果一位顾客的欲购商品疑似缺货,“请稍等,我去后台查一下”便是最常听到的一句话。随着在公共场所部署越来越多的自主机器,人们很快便会对其存

许多组织已经在开发基本框架以支持 CV 在日常操作中的使用,并通过连续的数据管道确保其模型具有适当数量的训练数据,以使其能够随着时间的推移而执行和改进。其中,有通用模型,或者针对特定场景采集标注的数据,例如家用扫地机器人,宠物摄像头,等。例如,通过计算机视觉,机器可以识别出冰面上的黑色冰球,但是球员的溜冰鞋可能会干扰该冰球的配准。配准:计算机将不同数据集转换至单个坐标系中,例如,从取自临床事件轨迹
人工智能不仅是指寻求如何替代人类的机器人或人类寻求自我挑战的游戏,更是指运用复杂的程序化数学,其结果与高质量的训练数据相结合,推动了我们在日常生活中所看到的技术进步。从无人驾驶汽车到寻找癌症的治疗方法,人工智能正在逐渐渗透我们的生活之中。以下是内容由“澳鹏 | AI与机器学习干货大本营”编辑,希望能帮助对人工智能领域感兴趣的学者或是专业人士,如果有任何遗漏也请随时回复我们,我们将及时更新!(按英语
具身智能正成为下一代AI发展核心,但面临高质量多模态数据不足的挑战。本期推荐两大核心数据集:1000小时机械臂遥操数据集(覆盖多场景任务,含多模态同步数据)和第一人称手部操作数据集(专业场景动作捕捉)。这些数据从通用智能形成、环境适应性及任务迁移三个维度,助力攻克跨模态融合、动态适应等瓶颈。澳鹏提供800+成品数据集,支持80+语言,持续为AI模型训练提供高质量数据解决方案。
随着AI编程助手向多步决策的CodeAgent演进,行业面临真实场景通过率不足45%的瓶颈。澳鹏精选三大代码类数据集解决方案:1)类SWE-Bench提供真实GitHub问题及补丁的端到端评测基准;2)CodeAgent交互数据记录AI决策全过程的思考-行动日志;3)真人轨迹数据集捕捉开发者解决复杂问题的完整策略。这些数据集覆盖主流编程语言,包含成功/失败案例,助力突破当前AI在代码定位、规范遵循
