




- @Alexa_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
根据报错内容可以看出Input type为torch.FloatTensor(CPU数据类型),而weight type(即网络权重参数这些)为torch.cuda.FloatTensor(GPU数据类型)。既然网络参数是GPU类型,那解决方法就是将输入类型转变为GPU类型,需要使用到cuda,没有cuda就解决不了。那就同理,对net进行转换。若与上面错误是反的,即。

视图框架:快速构建针对人工智能的 python 的 webApp 库,封装前端页面 + 后端接口 + AI 算法模型推理优势在于易用性,代码结构相比 Streamlit 简单,只需简单定义输入和输出接口即可快速构建简单的交互页面,更轻松部署模型。适合场景相对简单,想要快速部署应用的开发者;优势在于可扩展性,相比 Gradio 复杂。适合场景相对复杂,想要构建丰富多样交互页面的开发者。Gradio是
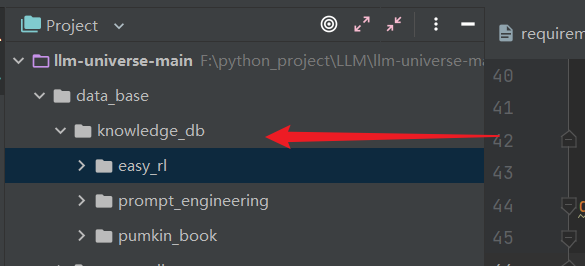
本项目是一个个人知识库助手项目,旨在,回答用户问题。个人知识库应当能够支持各种类型的数据,支持用户便捷地导入导出、进行管理。在我们的项目中,我们以 Datawhale 的一些经典开源课程作为示例,设计了多种文件类型,介绍每一种文件类型的处理方式,从而支持用户无难度地构建自己的知识库。
根据报错内容可以看出Input type为torch.FloatTensor(CPU数据类型),而weight type(即网络权重参数这些)为torch.cuda.FloatTensor(GPU数据类型)。既然网络参数是GPU类型,那解决方法就是将输入类型转变为GPU类型,需要使用到cuda,没有cuda就解决不了。那就同理,对net进行转换。若与上面错误是反的,即。

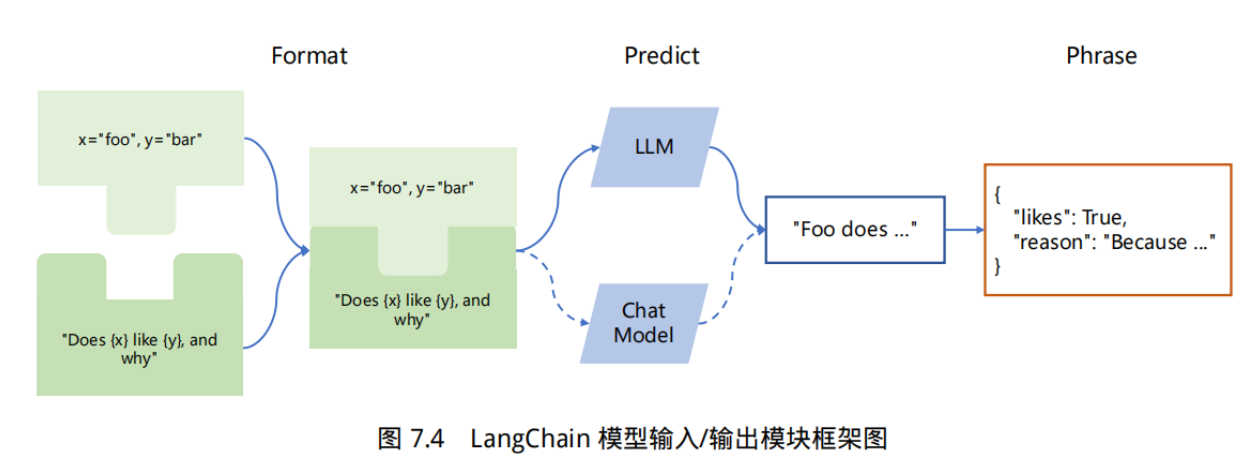
定义在用于发出请求的 call() / run() / apply() 方法中,例如 chain.call(inputs, callbacks=[handler]) ,它将仅用于该特定请求,以及它包含的所有子请求(例如,对 LLMChain 的调用会触发对 Model 的调用,该 Model 使用 call() 方法中传递的相同 handler)。因此,在本节中我们将介绍 LangChain 中的
如果大家在看过这么多年的卷子可以看到,有很多相同的地方。所以不用细纠是那一年那一年的卷子,重点是把那些基础知识点掌握。从题目难度上来看,计算题考的比较少,大多都是简答题,所以考的更多是对概念的理解。
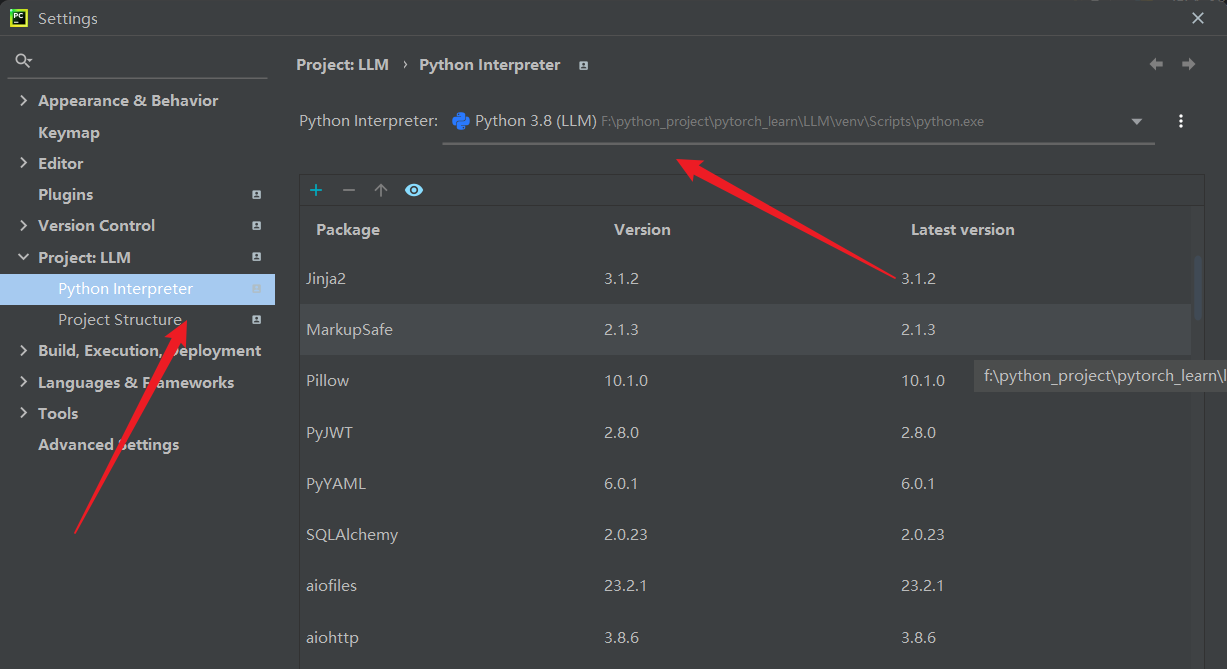
首先通过File—>Setting—>Project:【项目名称】—>Project Interpreter—>设置—>add—>Virtuallenv Environment配置虚拟环境即可。此次我的虚拟环境地址是 F:\python_project\pytorch_learn\LLM\venv。使用cd 到该文件夹下的Scripts中,输入activate.bat。当创建虚拟环境之后,需要给项
定义在用于发出请求的 call() / run() / apply() 方法中,例如 chain.call(inputs, callbacks=[handler]) ,它将仅用于该特定请求,以及它包含的所有子请求(例如,对 LLMChain 的调用会触发对 Model 的调用,该 Model 使用 call() 方法中传递的相同 handler)。因此,在本节中我们将介绍 LangChain 中的
Gradio 可以包装几乎任何 Python 函数为易于使用的用户界面。应用界面:gradio.Interface(简易场景), gradio.Blocks(定制化场景)输入输出:gradio.Image(图像), gradio.Textbox(文本框), gradio.DataFrame(数据框), gradio.Dropdown(下拉选项), gradio.Number(数字), gradio
