




- @AIMing_byte
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文是程序员转行学习AI大模型的第19个核心知识点笔记,附完整可运行代码。当前阶段:还在学习知识点,由点及面,从 0 到 1 搭建 AI 大模型知识体系中。
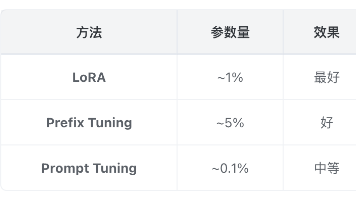
本文系统梳理了AI大模型微调的核心概念与技术路线。首先区分了预训练(通用知识学习)与微调(领域知识训练)两个阶段,将微调方法按数据类型分为监督微调(SFT)和偏好优化(PO),按参数量分为全量微调与PEFT(含LoRA、Prefix Tuning等方法)。重点对比了DPO与PPO两种偏好优化算法的优缺点,并给出问答系统、对话助手等场景的微调方案建议。文章为开发者提供了从理论到实践的完整微调知识框架
残差连接通过在神经网络中将输入直接与输出相加(y=F(x)+x),有效缓解了梯度消失问题。对比实验显示,无残差连接时梯度从1衰减到0.5,而有残差连接时梯度增强到1.5。这种设计保留了原始信息,使深层网络更易训练。代码实现展示了残差块的结构:输入经过线性变换和激活后,与原始输入相加输出。关键优势在于梯度可直接通过恒等路径传播,即使网络层数很深也能保持稳定的训练效果。
本文介绍了注意力机制的三个重要扩展版本。自注意力机制(self-attention)中Q、K、V来自同一序列,通过计算序列内部元素的相关性来捕捉特征。掩码注意力通过添加下三角掩码矩阵,实现只能关注已生成内容的功能,适用于序列生成任务。多头注意力则从多个角度并行计算注意力,将不同视角的特征拼接起来,增强模型的表达能力。文中通过搜索引擎查询的类比解释了这些机制的原理,并提供了对应的实现代码示例,展示了
本文介绍了注意力机制的三个重要扩展版本。自注意力机制(self-attention)中Q、K、V来自同一序列,通过计算序列内部元素的相关性来捕捉特征。掩码注意力通过添加下三角掩码矩阵,实现只能关注已生成内容的功能,适用于序列生成任务。多头注意力则从多个角度并行计算注意力,将不同视角的特征拼接起来,增强模型的表达能力。文中通过搜索引擎查询的类比解释了这些机制的原理,并提供了对应的实现代码示例,展示了
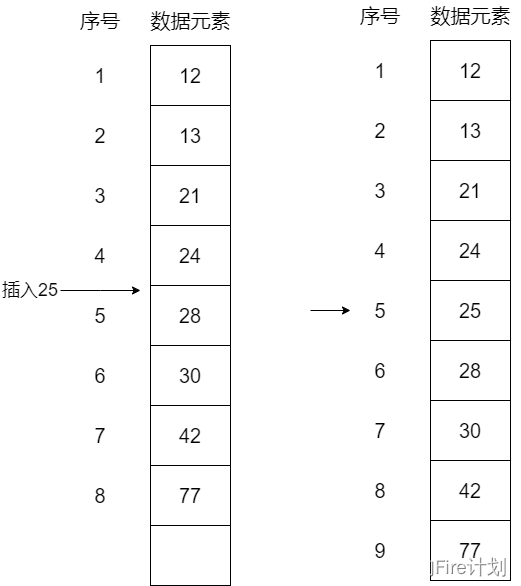
线性表,或称表,是一种非常灵便的结构,可以根据需要改变表的长度,也可以在表中任何位置对元素进行访问、插入或删除等操作。另外,还可以将多个表连接成一个表,或把一个表拆分成多个表。例如,26个英文字母的字母表:(A,B,C,......,Z)就是一个线性表,表中的数据元素是单个字母。在稍复杂的线性表中,一个数据元素可以包含若干个数据项。例如在学生基本信息表中,每个学生为一个数据元素,包括学号、姓名、性
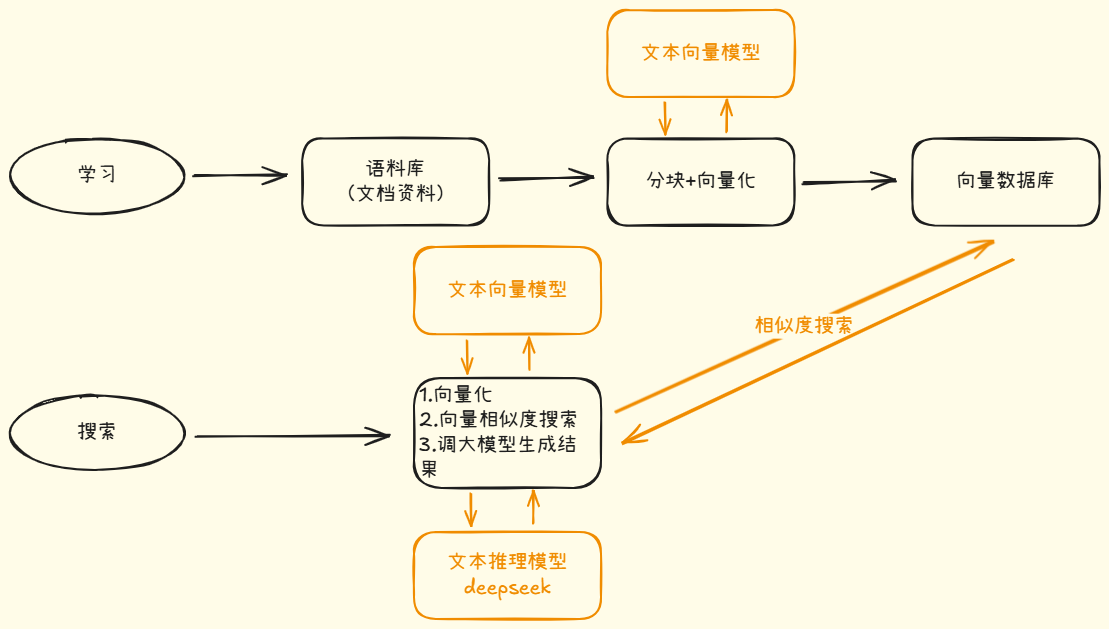
注意:在 Windows 下安装 Ollama 后,强烈建议通过配置环境变量来修改模型存储位置,不然就会默认存储在 C 盘目录下,而大模型文件一般都比较大。功能:将文本向量化后,存储到向量数据库中,这里用 Chroma 向量数据库,支持通过语义相似度进行搜索。功能:将分块后的文本,通过调用文本向量模型,进行向量化。功能:读取知识库文本文件,并将内容分割成多个段落块。功能:调用 AI 大模型,实现文
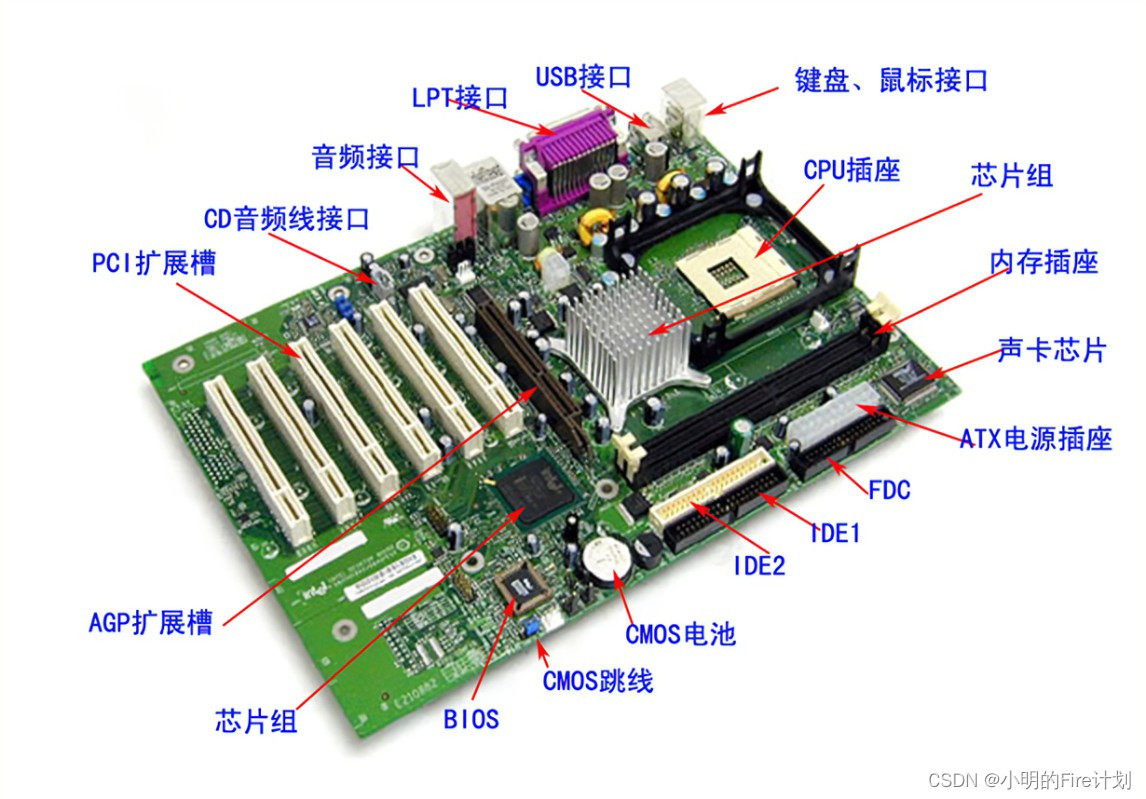
台式PC由主机和外部设备组成,主机由主板、CPU、内存条、显卡、网卡、声卡、插卡和插座、机箱和电源等组成。
在CSS3中,新增了3个背景属性。
