




- @2401_84182936
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据模型就是数据组织和存储的方法,通过抽象的实体以及实体间联系的形式来表达现实世界中事务的相互关系的一种映射,他强调从业务、数据存取和使用角度合理的存储数据。真实场景中,是lambda架构和kappa架构的混合。大部分实时指标通过kappa架构计算,少量关键指标用lambda架构批量计算随着数据多样性的发展,数据库这种提前规定schema的模式显得力不从心。这时出现了数据湖技术,把原始数据全部缓存

觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)**[外链图片转存中…(img-W1pSfZ14-1712566172477)]

现在,我们来看看具体的关联规则算法。关联规则最经典的算法有两个。
PB∣APB现在,我们来看看具体的关联规则算法。关联规则最经典的算法有两个。

因此,本文将基于Python爬虫技术,对淘宝渔具销售数据进行爬取和分析,并基于Django框架设计与实现一个可视化系统,以期为渔具销售行业提供有益的指导和参考,促进渔具行业的发展。1.销售数据挖掘与分析: 许多研究者对电商平台的销售数据进行挖掘和分析,主要应用数据挖掘和机器学习的方法,通过对用户行为和购买记录的分析和预测,提高销售效果和用户满意度。3.用户评论和评价分析: 淘宝平台上用户的评论和评

【5】数据集的标准化(本数据集特征比较接近,实际处理过程中未标准化)【6】构建训练集和测试集(本课暂不考虑验证集)
config.json由app、deviceConfig和module三个部分组成,缺一不可。在FA模型的应用开发过程中,需要在config.json配置文件中对应用的包结构进行声明。

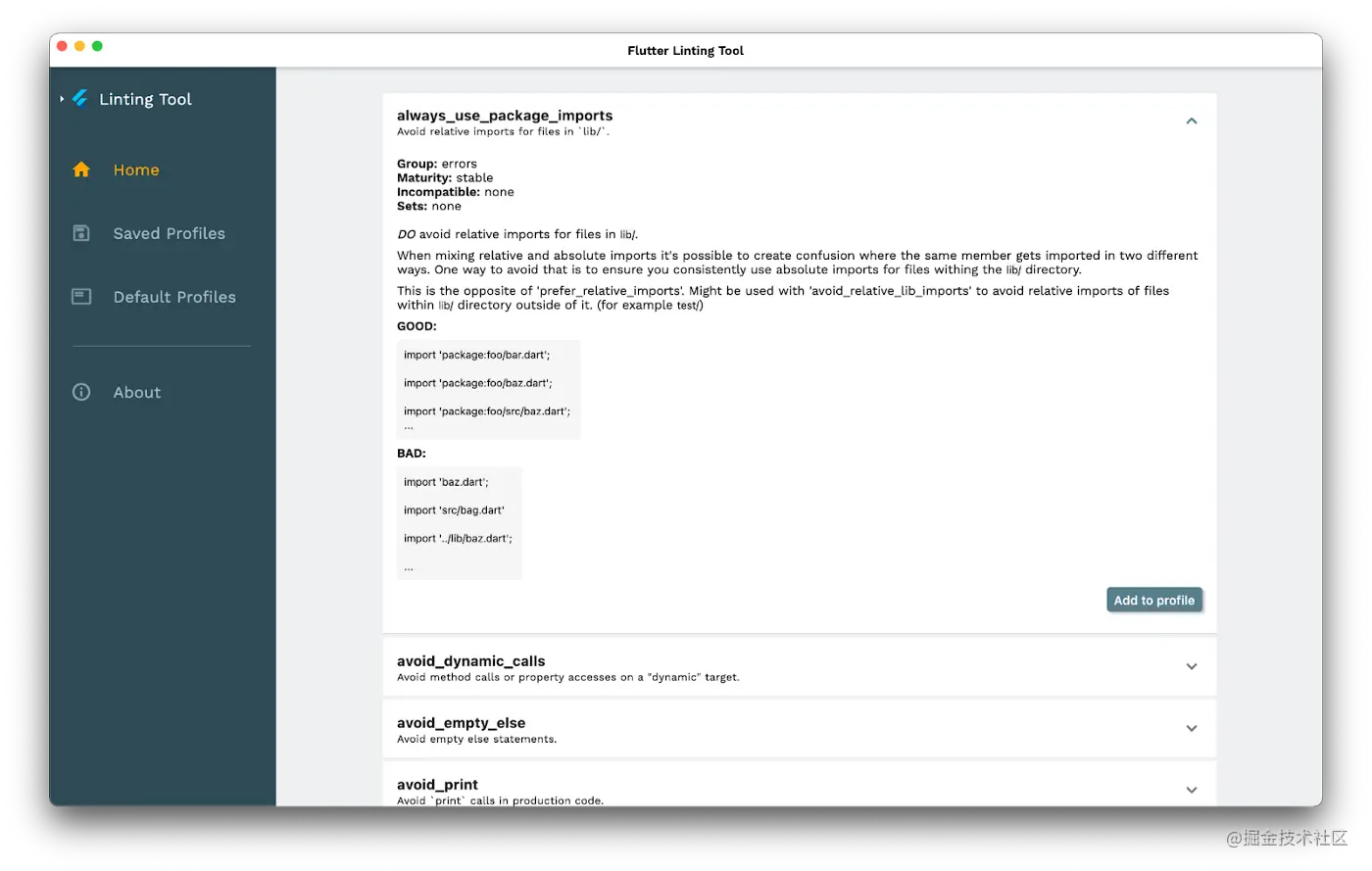
今年,在Flutter Engage上,Flutter的桌面支持的测试版快照被纳入了稳定频道。这导致了对样本 repo 的桌面样本的需求,该样本以后可以在桌面应用商店(如 macOS App Store、Microsoft Store 和 Linux Snap Store)发布。经过与Brett和团队的讨论,我们决定建立一个桌面样本,同时也是一个工具,帮助开发者管理他们项目的lint规则。请看Gi
觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)**[外链图片转存中…(img-W1pSfZ14-1712566172477)]
*多设备统一开发环境:**支持多种HarmonyOS设备的应用开发,包括手机(Phone)、平板(Tablet)、车机(Car)、智慧屏(TV)、智能穿戴(Wearable),轻量级智能穿戴(LiteWearable)和智慧视觉(Smart Vision)设备。
