




- @2401_84181309
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
有依赖关系的尽量放到同一台服务器(如:Ds-worker和Hive/Spark)
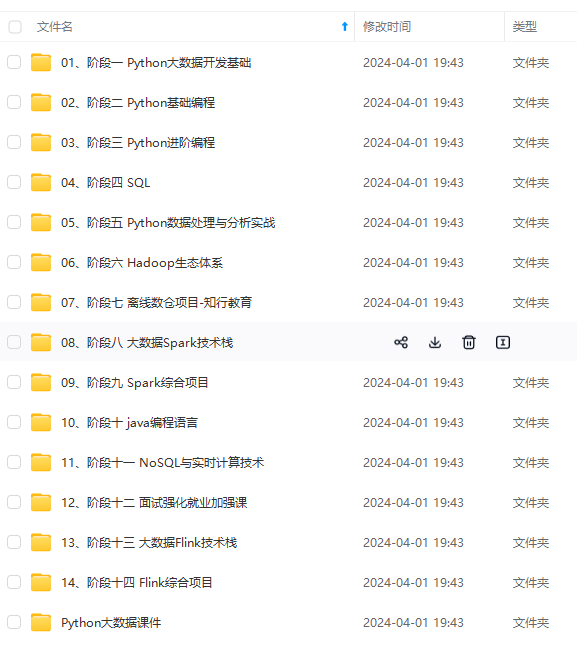
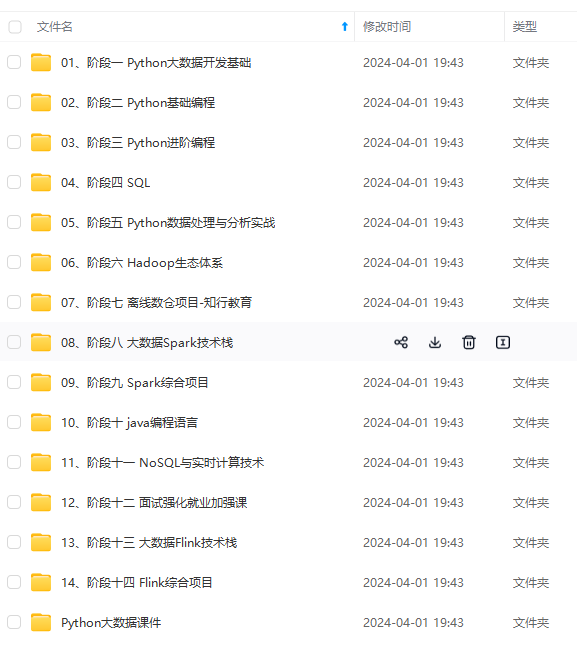
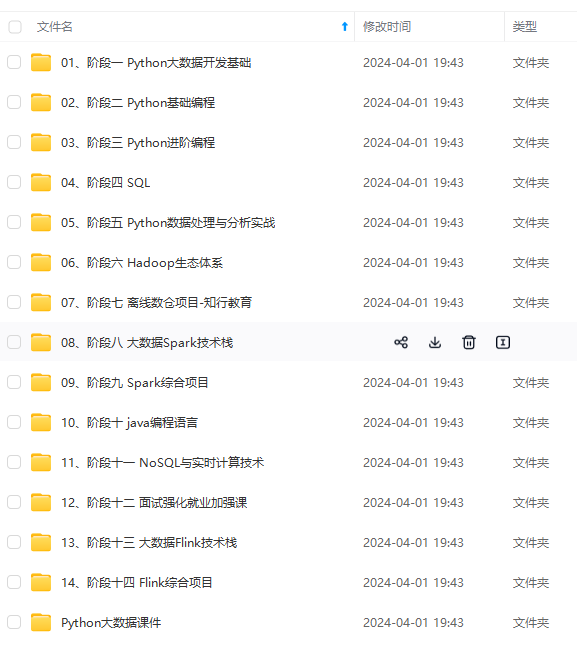
文章中涉及到的命令大家一定要像我一样每个都敲几遍,只有在敲的过程中才能发现自己对命令是否真正的掌握了。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新需要这份系统化资料的朋友,可以戳这里获取。

论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!命令把这个jar包下载到本地(

以下操作先在主机hadoop7上配置,配置完成后进入 /usr/local/hadoop-2.7.3/etc/hadoop目录下使用scp命令将配置好的hadoop-2.7.3和jdk1.8.0_144相关文件复制到hadoop8和hadoop9的 /usr/local/hadoop-2.7.3/etc/hadoop目录下。将修改好的mapreduce组件和Yarn组件配置文件用scp命令复制到h

print(“爬虫任务执行开始!company = “平台注册”# 定时任务,每隔10s执行1次。# return # 新增的。# return # 新增的。
它是一个文件系统,用于存储文件,通过目录树来定位文件;它是分布式的,有很多服务器联合起来实现其功能;适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。MapReduce是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件代码整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。MapReduce是一种分布式计算

这里参数十分丰富,以后将独自写一期docker bulid来详细介绍该功能的使用,属于制作镜像一块的,是比较大的一块docker内容。各大互联网大厂面试真题。从基础到入阶乃至原理刨析类面试题 应有尽有,赶快来装备自己吧!助你面试稳操胜券,solo全场面试官。可以通过–help查看每一个Image命令的详细信息。很多学Python伙伴问题有没有体系的面试题?仅输出image的IMAGE ID。显示所

有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(HarmonyOS NEXT)资料用来跟着学习是非常有必要的。这份鸿蒙(HarmonyOS NEXT)资料包含了鸿蒙开发必掌握的核心知识要点,内容包含了。

AUTH_TYPE_BIOMETRIC_FINGERPRINT_ONLY指纹识别,AUTH_TYPE_BIOMETRIC_FACE_ONLY脸部识别以及AUTH_TYPE_BIOMETRIC_ALL指纹和面部。// BiometricAuthentication.SecureLevel 2D人脸识别建议使用SECURE_LEVEL_S2,3D人脸识别建议使用SECURE_LEVEL_S3。// 5
