




- @2302_80560244
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
简单来说,模型内置了 512 个专用专家模块,这些模块会在 4 个共享专家模块的协调下 “按需工作”—— 门控网络以 FP16 精度实时判断数据处理需求,确定哪些模块需要协同,再将计算产生的梯度回传给稀疏注意力层,最终实现 “精准激活、减少冗余” 的效果。8 月 13 日深度求索发布的 DeepSeek-R2 模型,首次将医药研发的靶点筛选时间从 72 小时压缩至 8 小时,其效率提升对缩短医药研

简单来说,模型内置了 512 个专用专家模块,这些模块会在 4 个共享专家模块的协调下 “按需工作”—— 门控网络以 FP16 精度实时判断数据处理需求,确定哪些模块需要协同,再将计算产生的梯度回传给稀疏注意力层,最终实现 “精准激活、减少冗余” 的效果。8 月 13 日深度求索发布的 DeepSeek-R2 模型,首次将医药研发的靶点筛选时间从 72 小时压缩至 8 小时,其效率提升对缩短医药研
百度蒸汽机(MuseSteamer)音视频一体化模型完成重大升级,Turbo 版、Lite 版、Pro 版及有声版全面开放,首次实现多人有声音视频一体化生成,为 AI 视频领域开辟新赛道。

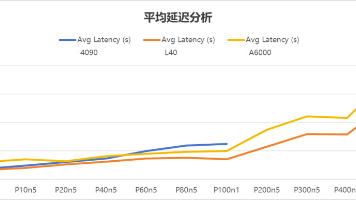
因此,即使在相同的服务器上,不同环境下的数据可能会有细微的差异。吞吐量是衡量GPU处理能力的关键指标,它代表着GPU每秒能处理的Token数量,数值越高,处理速度就越快,就像工厂里效率超高的生产线。,即使在300并发的“大场面”下,仍能保持流畅,就像一家服务周到的高级餐厅,无论多忙都能及时响应顾客需求。延迟直接关系到用户体验,它反映了从发出请求到收到响应的时间,就像你在餐厅点菜后等待上菜的时间,越
智能小 Q 的核心突破是让 Agent 具备‘理解 - 分析 - 输出’的闭环能力,而 GPU 云主机的高算力密度,是实现‘10 秒响应、20 分钟出报告’的关键基础设施。8 月 28 日,阿里巴巴旗下瓴羊正式发布国内首个数据分析 Agent——Quick BI “智能小 Q” 升级版,该产品通过问数、解读、报告三大 Agent 协同,将企业数据分析从 “小时级” 压缩至 “分钟级”,标志着 AI

智能小 Q 的核心突破是让 Agent 具备‘理解 - 分析 - 输出’的闭环能力,而 GPU 云主机的高算力密度,是实现‘10 秒响应、20 分钟出报告’的关键基础设施。8 月 28 日,阿里巴巴旗下瓴羊正式发布国内首个数据分析 Agent——Quick BI “智能小 Q” 升级版,该产品通过问数、解读、报告三大 Agent 协同,将企业数据分析从 “小时级” 压缩至 “分钟级”,标志着 AI
能够为用户带来更流畅、更持久的使用体验,无论是多任务处理、大型游戏运行,还是复杂的 AI 运算,都能轻松应对。,当前消费者对智能手机的AI 功能越来越看重,AI 技术已成为影响购买决策的重要因素;,最终受益的将是广大消费者。,可能会吸引部分对 AI 功能敏感的用户群体,Apple此番滞后操作,,内部密封去离子水,能通过蒸发冷却为 A19 Pro 芯片散热,配合。,这也是导致相关功能延迟上线的重要原

智能小 Q 的核心突破是让 Agent 具备‘理解 - 分析 - 输出’的闭环能力,而 GPU 云主机的高算力密度,是实现‘10 秒响应、20 分钟出报告’的关键基础设施。8 月 28 日,阿里巴巴旗下瓴羊正式发布国内首个数据分析 Agent——Quick BI “智能小 Q” 升级版,该产品通过问数、解读、报告三大 Agent 协同,将企业数据分析从 “小时级” 压缩至 “分钟级”,标志着 AI
百度蒸汽机(MuseSteamer)音视频一体化模型完成重大升级,Turbo 版、Lite 版、Pro 版及有声版全面开放,首次实现多人有声音视频一体化生成,为 AI 视频领域开辟新赛道。
英伟达Jetson AGX Thor™开发者套件及量产级模组全面上市,AI机器人市场会迎来怎样的变动呢?3分钟一文迅速了解
