- @2201_75345884
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
CBOW(Continuous Bag-of-Words)模型是一种用于生成词向量的神经网络模型,它基于上下文预测目标词。其核心思想是:给定一个目标词的上下文单词,通过模型预测该目标词。在训练过程中,模型会不断调整参数,使得预测结果尽可能接近真实的目标词,最终训练得到的词向量能够捕捉单词之间的语义关系。

MNIST数据集是机器学习领域中非常经典的图像数据集,它包含了70,000张手写数字图像,其中60,000张用于训练,10,000张用于测试。这些图像均为灰度图,尺寸是28×28像素,并且已经进行了居中处理,大大减少了预处理的工作量,同时也加快了模型的运行速度。在本文的实战中,MNIST数据集将作为我们训练和测试残差网络的“战场”。# 模块搭建# 网络搭建return x在上述代码中,首先定义了R

在食物图像分类项目中,学习率调整策略对模型性能提升起到了关键作用。动态调整学习率使模型能够在训练的不同阶段自适应地调整参数更新步长,平衡训练速度与收敛效果。除了StepLR,还有等多种学习率调整策略,每种策略都有其独特的适用场景。未来,可以进一步探索不同学习率调整策略在食物图像分类中的应用,结合数据增强、网络结构优化等技术,持续提升模型性能。

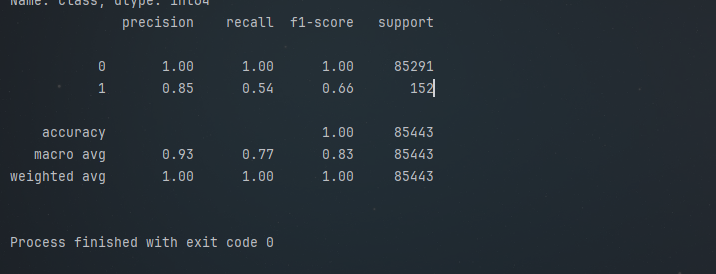
通过以上步骤,我们成功地将逻辑回归算法应用于信用卡欺诈检测任务中,从数据读取、预处理,到模型构建、训练与评估,完整地展示了一个机器学习项目的开发流程。逻辑回归凭借其简单易懂、可解释性强的特点,在金融风控领域有着广泛的应用。然而,实际应用中可能存在数据不均衡、特征优化等问题,后续可以尝试采用过采样、欠采样等技术解决数据不均衡问题,或者运用特征工程方法挖掘更有效的特征,进一步提升模型的性能。希望本文能
本项目使用的食物图像数据集包含20类不同的食物,如八宝粥、巴旦木、白萝卜等。数据集分为训练集和测试集,分别用于模型的训练和评估。每类食物都有一定数量的图像样本,这些图像涵盖了不同角度、光照条件下的食物外观,为模型的训练提供了丰富的多样性。nn.Conv2d(stride=1,padding=2,),nn.ReLU(),nn.ReLU(),nn.ReLU()定义了一个名为CNN的类,继承自nn.Mo

MNIST数据集是深度学习领域经典的入门数据集,包含70,000张手写数字图像,其中60,000张用于训练,10,000张用于测试。这些图像均为灰度图,尺寸是28x28像素,并且已经做了居中处理,这在一定程度上减少了预处理的工作量,能够加快模型的训练和运行速度。nn.Conv2d(stride=1,padding=2),nn.ReLU(),nn.ReLU(),nn.ReLU(),nn.ReLU()
本项目使用的食物图像数据集包含20类不同的食物,如八宝粥、巴旦木、白萝卜等。数据集分为训练集和测试集,分别用于模型的训练和评估。每类食物都有一定数量的图像样本,这些图像涵盖了不同角度、光照条件下的食物外观,为模型的训练提供了丰富的多样性。nn.Conv2d(stride=1,padding=2,),nn.ReLU(),nn.ReLU(),nn.ReLU()定义了一个名为CNN的类,继承自nn.Mo
MNIST数据集是深度学习领域经典的入门数据集,包含70,000张手写数字图像,其中60,000张用于训练,10,000张用于测试。这些图像均为灰度图,尺寸是28x28像素,并且已经做了居中处理,这在一定程度上减少了预处理的工作量,能够加快模型的训练和运行速度。nn.Conv2d(stride=1,padding=2),nn.ReLU(),nn.ReLU(),nn.ReLU(),nn.ReLU()
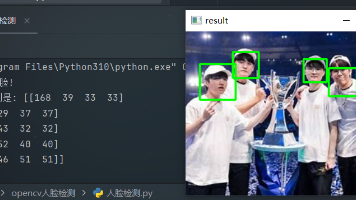
OpenCV 中的人脸检测主要基于 Haar 级联分类器。Haar 级联分类器是一种基于机器学习的目标检测方法,它使用 Haar 特征来描述目标的外观,并通过级联结构来快速排除非目标区域。Haar 特征:Haar 特征是一种简单的矩形特征,它通过计算图像中不同区域的像素值差异来描述图像的局部特征。常见的 Haar 特征包括边缘特征、线性特征和中心特征等。积分图:为了快速计算 Haar 特征,Ope
loss_fn=nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果optimizer=torch.optim.Adam(model.parameters(),lr=0.01) #创建一个优化器# #params:要训练的参数,一般我们传入的都是model.parameters()# lr:learning_rate学习率,也就