




- @zjm521521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
什么是维度?什么是指标?指标有哪几种分类?维度定义:维度是度量的环境,用来反映业务的一类属性。这类属性的集合构成一个维度,也可以称为实体对象。维度属于一个数据域,如地理维度(包括国家、地区、省、城市等)、时间维度(包括年、季、月、周、日等),商品的种类也是一个维度。特点:维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实”,将环境描述为“维度”。维度是用于分析事实所需要的多样环境。例如,在

PostgreSQL(有时也被称为“Postgres”或简称为“PG”)是一个强大的、开源的对象-关系数据库管理系统(ORDBMS)。它使用了和许多其他SQL数据库管理系统(如MySQL、SQLServer、Oracle等)相似的查询语言,但它也提供了许多扩展功能,如复杂查询、外键、触发器、视图、事务完整性、多版本并发控制(MVCC)等。扩展性:PostgreSQL支持大量的扩展,这些扩展可以增加
数仓工具Data X 的使用!使用DataX是如何进行数据的传输也就是说怎么从mysql或者是SQLserver数据库将数据传输到hive数仓中!Data X怎么使用!数据的同步方式!

企业数字化转型(Digital Transformation)是指企业利用数字技术(如云计算、大数据、人工智能、物联网等)来革新其商业模式、运营流程、产品和服务,以提升效率、优化客户体验、创造新的价值,并最终实现业务增长和竞争优势的过程。企业数字化转型是一个持续的过程,它需要企业在多个方面做出改变,从思维模式到实际操作。成功的数字化转型不仅依赖于技术的选择和实施,更取决于企业是否能够灵活应对变化,

FIneBI是可视化的工具!首先我们要知道可视化的是什么?我们大数据常说的可视化的数据。例如:将我们数据库的数据进行可视化。
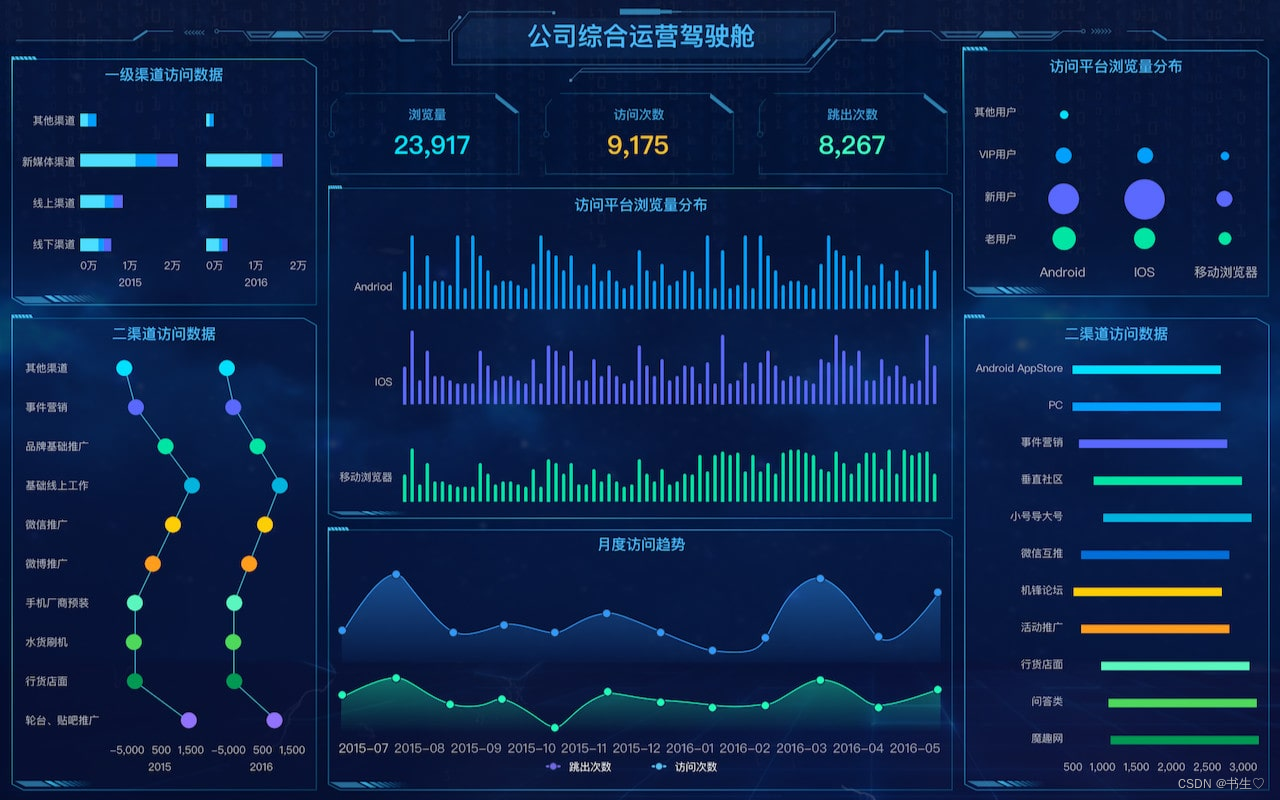
15个电商数据分析模型,助力精准决策 本文系统梳理了电商运营中的15个核心数据分析模型,涵盖用户价值分析、GMV增长、品类运营和营销优化四大体系。重点介绍了RFM用户分层、GMV漏斗拆解、波士顿矩阵等经典模型在不同电商平台(阿里、抖音、快手等)的应用场景。通过实际案例解析,展示了如何运用这些模型精准定位高价值用户、优化营销投放、提升品类销售和改善运营效率,为电商从业者提供了一套完整的数字化决策方法
《深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存》在 Apache Spark 中,Shuffle 是一个关键的概念,它涉及到数据的重新分布,通常发生在宽依赖操作中,例如groupByKeyjoin等。mapreduce的shuffle作用: 将map计算后的数据传递给reduce使用mapreduce的shuffle过程: 分区,排序,合并(规约)Shuffle 的定义Shuf

【数据分析---- Pandas进阶指南:核心计算方法、缺失值处理及数据类型管理】 !!!!!在 Pandas 中,Timedelta类型用于表示两个日期时间之间的差值。这种类型非常有用,尤其是在处理时间序列数据时。下面是一些关于Timedelta类型的基础知识和示例。创建 Timedelta 对象可以使用或者字符串来创建Timedelta对象。使用创建# 创建 Timedelta 对象print

Apache Spark是专为大规模数据处理而设计的快速通用的分布式计算引擎(基于内存),是开源的类Hadoop MapReduce的通用分布式计算框架。和MapReduce一样,都是完成大规模数据的计算处理。Spark 被设计用于处理诸如==批处理、流处理、机器学习、图计算==等多种类型的数据处理任务,并且可以在各种数据源上运行,包括结构化与非结构化的数据。

数据分析的介绍,Python开源库,配置Jupyter!!!定义:数据分析是指使用适当的统计方法和技术对收集来的数据进行系统的检查、清理、转换和建模,以揭示其中的趋势、模式和结论的过程。数据分析的主要目标是从数据中提取有用的信息,以支持决策制定和问题解决
