




- @zj51050_heartxy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
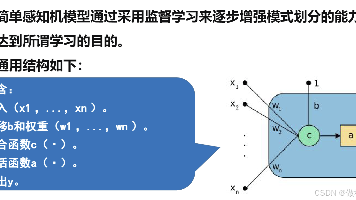
摘要:感知机是最基础的神经网络模型,由输入层、权重、偏置和激活函数四部分组成,采用"输入→加权求和→激活输出"的工作流程。核心作用是模拟神经元决策逻辑,通过监督学习调整参数实现分类。文章详细解析了感知机的结构原理、激活函数类型(如阶跃函数、ReLU函数),并通过苹果香蕉分类和数值计算案例演示其应用。尽管感知机只能处理线性可分问题(无法解决异或问题),但它为多层感知机和深度学习奠
摘要:本文介绍了度量学习在机器学习中的核心作用,它通过优化距离度量来解决传统欧氏距离"一刀切"的问题。文章详细讲解了加权欧氏距离和马氏距离的原理:加权欧氏距离通过调整特征权重突出关键特征,马氏距离则能消除特征相关性。配合Python代码实践,展示了在"好瓜分类"任务中,改进后的距离度量可使KNN分类精度提升5%-15%。度量学习在图像检索、推荐系统等场景中具

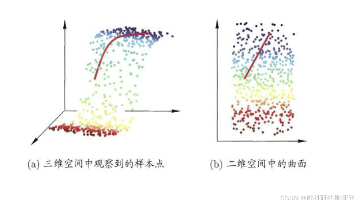
本文介绍了机器学习中的降维技术,重点讲解了高维数据的"维度灾难"问题及其解决方案。文章首先解释了维度的概念和维度灾难的危害,包括欧式距离失效、数据稀疏性以及计算成本飙升等问题。然后阐述了降维的本质是将高维数据映射到低维空间,同时保留关键信息。最后详细介绍了经典降维算法MDS(多维缩放)的原理和实现步骤,包括距离矩阵计算、低维坐标求解等核心过程,并通过Python代码演示了如何将
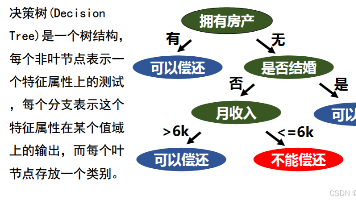
本文通过银行贷款案例直观介绍了决策树算法的核心逻辑。决策树是一种基于树形结构的分类方法,通过逐步测试特征属性(非叶节点)和分支选择,最终到达代表分类结果的叶节点。文章以银行贷款审批为例,展示了如何从根节点开始,根据用户特征(房产、婚姻、收入)一步步判断还款能力。决策树的优势在于将复杂问题分解为简单判断流程,无需复杂计算,易于理解和应用。入门者只需掌握"从根到叶"的判断流程,就能
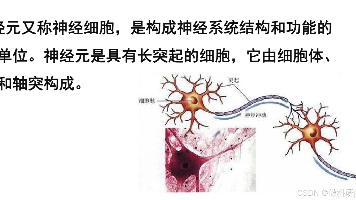
本文介绍了神经网络的核心概念和工作原理,从生物神经元的结构与信号传递机制出发,逐步拆解人工神经元(感知机)的数学模型。主要内容包括:1)生物神经元的结构(树突、细胞体、轴突)和"输入-整合-输出"的工作逻辑;2)人工神经元的数学建模(输入、权重、激活函数、输出);3)从单个人工神经元到多层神经网络的构建方法;4)神经网络的两个核心过程:前向传播(预测)和反向传播(训练优化);5
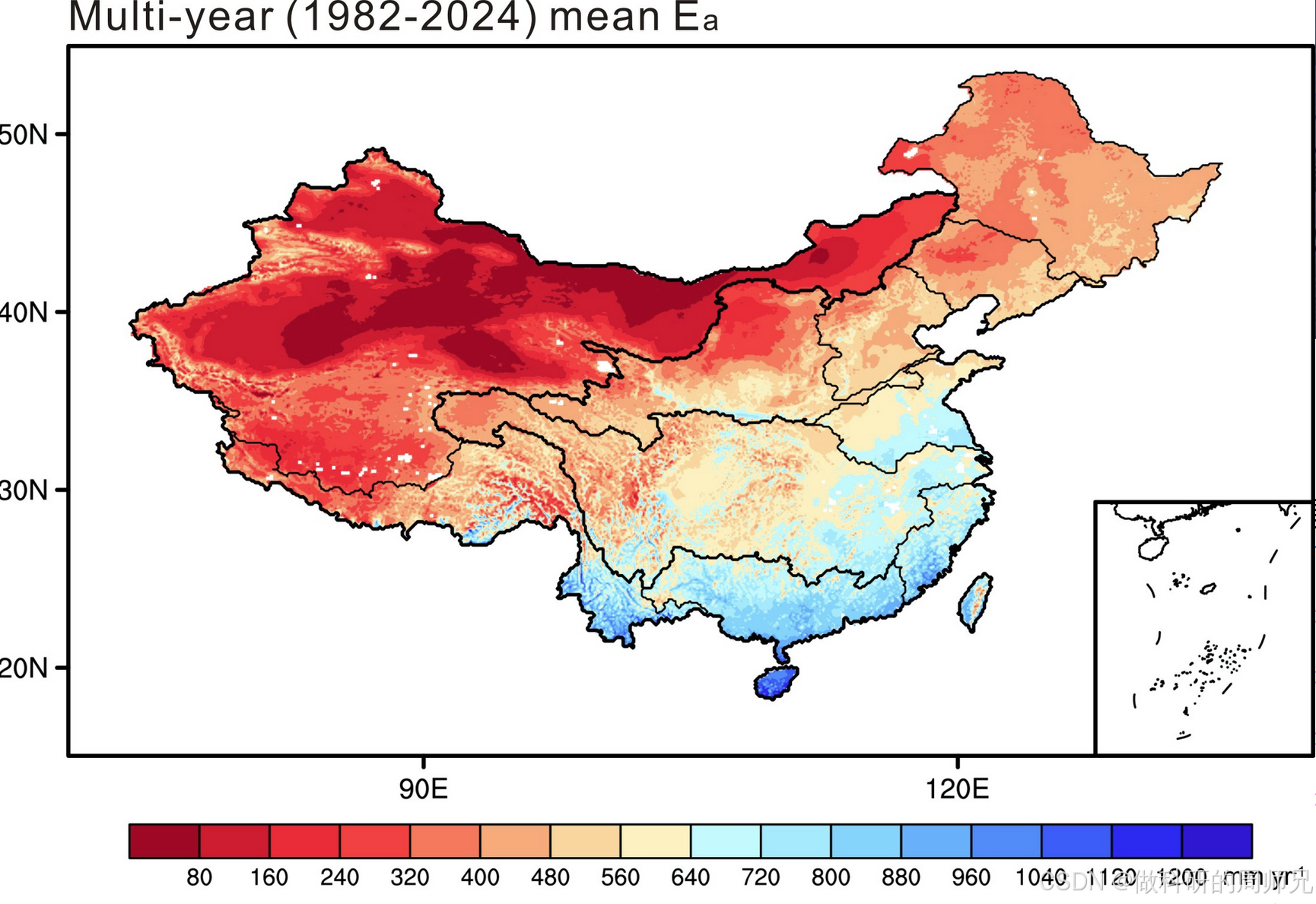
摘要:中国陆地蒸散发数据集v2.0(1982-2024)是基于蒸散发互补方法研制,采用CMFDv2和ERA5-Land等输入数据生成的0.1°分辨率月尺度数据产品。数据集包含551.16MB的NetCDF格式文件,记录中国陆地实际蒸散发量(mm/month),适用于水循环和气候变化研究。数据通过申请获取,需引用马宁(2019)在《Journal of Geophysical Research》和《
《中国玉米种植分布数据集(2001-2024)》是基于多源遥感数据构建的高精度农业数据集,包含22个省级行政区的30米分辨率玉米分布图(GeoTIFF格式)。数据集采用TWDTW算法生成,总体精度达80.06%,县域尺度R²为0.657-0.903。数据分两阶段构建:2001-2020年基于MODIS/LandsatNDVI,2021-2023年基于Landsat/Sentinel-2NDVI。该
北京大学全球变化与陆地生态系统模型研究团队更新发布了中国三大主粮作物空间分布数据集(2024版),包括冬小麦(30米)、玉米(30米)、单季稻(10/20米)和双季稻(10米)种植数据。该数据集在原有年份基础上延展至2024年,优化了数据格式便于使用,采用GeoTIFF文件格式和WGS84坐标系。研究成果已发表于ESSD、ScientificData等期刊,为农业监测和粮食安全研究提供了重要数据支
摘要:ChinaHighPM2.5数据集是中国高分辨率近地表PM2.5数据产品,覆盖2000-2023年全国范围,采用人工智能技术融合卫星、地基观测等多源数据生成。该数据集具有1km空间分辨率和日/月/年时间分辨率,数据精度达R²=0.92,RMSE=10.76μg/m³。数据以NetCDF格式存储,提供多种编程语言的格式转换代码,需按规范引用。该成果发表于《Remote Sensing of E
主成分分析(PCA)是一种无监督的线性降维方法,通过寻找数据方差最大的方向作为主成分,将高维数据投影到低维空间,同时保留数据的关键信息。PCA的核心逻辑包括两个等价性质:最近重构性(投影后能最小误差还原原始数据)和最大可分性(投影后方差最大化)。使用PCA前需对数据进行标准化处理,避免量纲差异影响结果。该方法能有效解决高维数据带来的计算成本高、过拟合等问题,并简化数据可视化。在机器学习领域,PCA
