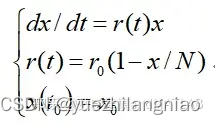- @yuezhilangniao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了AI智能体全栈开发的工程化规范,采用Skill-Centric设计体系,将功能模块化为独立技能单元。规范详细说明了基于FastAPI的后端架构,包含API网关层、智能体服务层和数据存储层,并重点介绍了自动生成TypeScript客户端的方法,确保前后端类型安全与编码一致性。文章还涵盖了开发工作流、监控保障及部署运维的最佳实践,为AI智能体开发提供了完整的工程化解决方案。

本文记录了某专科医院老旧数据库迁移的实战经验,涉及Oracle 10g/11g和SQL Server 2008/2012的无密码登录方法、使用Kettle进行跨库数据迁移的技术方案,以及处理数据类型转换、数据结构梳理等关键挑战。文章详细介绍了如何通过操作系统认证绕过密码限制,利用Kettle工具实现表结构复制和数据迁移,并分享了生成"60分数据字典"的实用方法。最后总结了迁移过程中的常见问题和时间

本文介绍了一个功能完善的MySQL 8.0.32二进制安装脚本,适用于Rocky Linux/CentOS 8+等RHEL系列操作系统。该脚本具有幂等性、本地包优先支持、详细错误处理和手动修复指南等特性,主要功能包括:自动安装依赖、创建用户、解压安装包、初始化数据库、配置systemd服务等。脚本提供多种使用选项,如指定root密码、使用本地安装包、重新初始化、卸载和查看状态等。关键错误场景会输出

摘要 本文档演示了ProxySQL与MySQL MGR的集成使用,重点展示了三种连接方式的区别: ProxySQL管理端(6032):使用admin用户配置ProxySQL规则,查看配置表而非业务数据 ProxySQL业务端(6033):通过业务用户liulaoshi访问实际数据,实现读写分离 MySQL直连(3306):绕过ProxySQL直接访问数据库 核心步骤包括: 在MySQL主库创建li

摘要 Linux“一切皆文件”的核心在于统一的访问接口而非存储介质。通过虚拟文件系统(VFS)这一抽象层,Linux将磁盘文件、进程信息、硬件设备等不同实体都抽象为文件接口(open/read/write)。其中: /proc下的伪文件动态映射内核数据结构 /dev设备文件通过主/次设备号关联驱动程序 /proc/[pid]/fd展示进程打开的文件描述符 这些“假文件”不占用磁盘空间,访问时由内核

eBPF:从内核技术到生产级基础设施的演进之路 摘要:eBPF作为革命性的Linux内核扩展技术,实现了安全高效的内核态编程,正在重塑云原生基础设施。本文通过三大生产场景分析其价值:1)云原生网络性能加速,相比传统方案降低50%延迟和60%CPU开销;2)下一代安全防护,支持7.3Tbps级DDoS防御和微秒级响应;3)LLM异构计算可观测性,实现零侵扰的全栈性能剖析。技术对比显示,eBPF与K8

本文解析了LangChain框架中的三大模型组件(LLMs、聊天模型、嵌入模型)的技术关系。三者虽然都基于Transformer架构,但因训练目标不同而分化:嵌入模型专注文本向量化,LLM专注文本生成,聊天模型优化对话交互。LangChain将这些独立发展的技术整合为统一接口,类似将不同功能的"工具刀"包装成标准化工具集。实际部署时可独立运行也可混合部署,轻量方案可共享服务器资

本文介绍了LangChain 1.x的核心新特性,包括: 统一Agent创建方式:使用create_agent统一入口,简化了Agent构建流程 中间件体系:支持插入自定义逻辑,如人工审批、自动摘要、敏感信息处理等 工具定义改进:通过@tool装饰器结合Pydantic实现参数校验和文档理解 记忆系统:提供短期记忆(Checkpointer)和长期记忆(Store)支持 文中包含可直接复用的代码示

本文总结了使用Ansible管理多版本Python环境的实战经验,重点解决了版本兼容性问题。文章首先描述了混合云环境下的自动化需求,详细记录了从Ansible安装、主机配置到遇到的ModuleNotFoundError和SyntaxError等典型问题的排查过程。针对不同Python版本(2.7/3.6/3.12)的兼容性问题,提出了两种解决方案:回退到Python2或升级Python3版本。最后

数学建模是指在解决实际问题时构建数学模型的过程;数学模型是在数学学科中产生的理论成果,而将这些成果应用到各学科中,并产生价值的过程就是数学建模。