




- @xwd127429
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
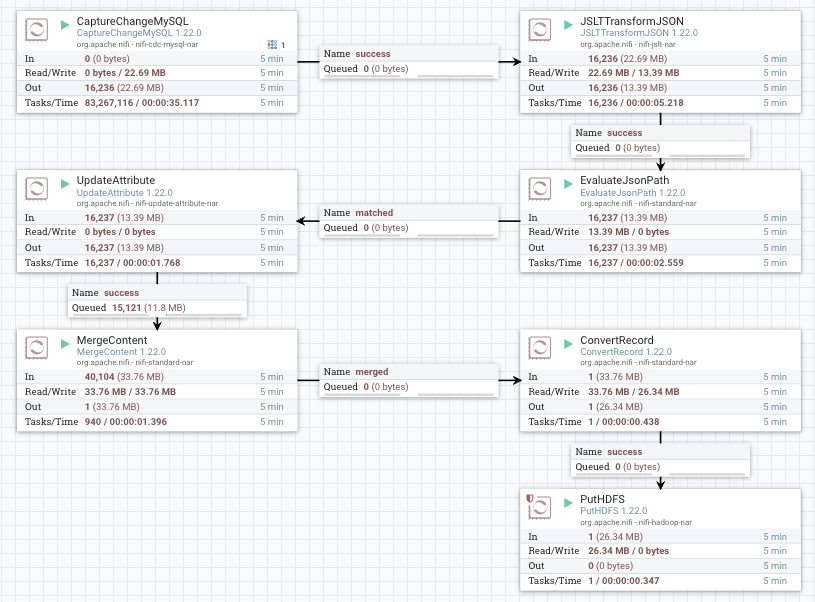
NiFi数据流实践:实时获取Mysql CDC数据,写入HDFS/Hive。NiFi版本:1.22.0。NiFi官方文档提供了详细的概念说明和使用说明,耐心通读一遍,就可以快速上手开发NiFi数据流。
在日常工作中,经常要通过ssh连接远程服务器,每次连接都输入密码,会比较麻烦。在Window系统上,我习惯使用xshell管理连接,非常方便。在MacOS系统上,没有xshell,而一些类似xshell的工具中,好用的要收费,免费的不好用,于是决定使用iTerm2打造一个好用的ssh神器,提高日常工作效率。话不多说,直接上干货。使用iTerm2打造ssh神器,主要是通过Profiles功能,每个P
描述Ambari注册主机的时候,ambari-agent出现如下错误:NetUtil.py:96 - EOF occurred in violation of protocol (_ssl.c:579)NetUtil.py:97 - SSLError: Failed to connect. Please check openssl library versions.解决在ambari-...
在模式识别,数据挖掘,机器学习等领域,距离度量和相似度度量有着很广泛的应用,对这些度量算法有一定程度的理解,可以帮助我们更好的处理和优化在这些领域遇到的问题。距离度量算法和相似度度量算法是基础算法,经常被用在其他更高级的算法中。比如K最近邻(KNN)和K均值(K-Means)可以使用曼哈顿距离或者欧式距离作为度量方法。本文介绍一些常见的距离度量算法和相似度度量算法。算法定义描述,部分内容摘自百度百
spark-submit提交python任务,使用指定的python环境参考spark Configuration,有如下描述:配置描述spark.pyspark.driver.pythonPython binary executable to use for PySpark in driver. (default is spark.pyspark.python)s...
Java连接HBase的方法,包含Kerberos认证。代码示例:package com.example.hbase.admin;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.